Функции сортировки sort и sorted
Содержание:
- Введение
- The Old Way Using Decorate-Sort-Undecorate¶
- Как получить значение списка по индексу?
- Дополнительные заметки о сортировке в Python
- Алгоритм быстрой сортировки
- 2 Срезы
- Maintaining Sort Order
- Что такое списки?
- Встроенные функции сортировки на Python
- Методы списков
- Реализация
- Key Functions
- Sorting a List of Strings
- Задания для самоподготовки
- Обзор возможностей программы
- Параметр key
- The Old Way Using Decorate-Sort-Undecorate
- Входные данные не меняются
Введение
Быстрая сортировка — популярный алгоритм сортировки, который часто используется вместе с сортировкой слиянием. Это алгоритм является хорошим примером эффективного алгоритма сортировки со средней сложностью O(n logn). Часть его популярности еще связана с простотой реализации.
Быстрая сортировка является представителем трех типов алгоритмов: divide and conquer (разделяй и властвуй), in-place (на месте) и unstable (нестабильный).
- Divide and conquer: Быстрая сортировка разбивает массив на меньшие массивы до тех пор, пока он не закончится пустым массивом, или массивом, содержащим только один элемент, и затем все рекурсивно соединяется в сортированный большой массив.
- In place: Быстрая сортировка не создает никаких копий массива или его подмассивов. Однако этот алгоритм требует много стековой памяти для всех рекурсивных вызовов, которые он делает.
- Unstable: стабильный (stable) алгоритм сортировки — это алгоритм, в котором элементы с одинаковым значением отображаются в том же относительном порядке в отсортированном массиве, что и до сортировки массива. Нестабильный алгоритм сортировки не гарантирует этого, это, конечно, может случиться, но не гарантируется. Это может быть важным, когда вы сортируете объекты вместо примитивных типов. Например, представьте, что у вас есть несколько объектов Person одного и того же возраста, например, Дейва в возрасте 21 года и Майка в возрасте 21 года. Если бы вы использовали Quicksort в коллекции, содержащей Дейва и Майка, отсортированных по возрасту, нет гарантии, что Дейв будет приходить раньше Майка каждый раз, когда вы запускаете алгоритм, и наоборот.
The Old Way Using Decorate-Sort-Undecorate¶
This idiom is called Decorate-Sort-Undecorate after its three steps:
-
First, the initial list is decorated with new values that control the sort order.
-
Second, the decorated list is sorted.
-
Finally, the decorations are removed, creating a list that contains only the
initial values in the new order.
For example, to sort the student data by grade using the DSU approach:
>>> decorated = >>> decorated.sort() >>> student for grade, i, student in decorated # undecorate
This idiom works because tuples are compared lexicographically; the first items
are compared; if they are the same then the second items are compared, and so
on.
It is not strictly necessary in all cases to include the index i in the
decorated list, but including it gives two benefits:
-
The sort is stable – if two items have the same key, their order will be
preserved in the sorted list. -
The original items do not have to be comparable because the ordering of the
decorated tuples will be determined by at most the first two items. So for
example the original list could contain complex numbers which cannot be sorted
directly.
Another name for this idiom is
Schwartzian transform,
after Randal L. Schwartz, who popularized it among Perl programmers.
Как получить значение списка по индексу?
У каждого элемента списка есть свой уникальный номер. Этот номер называется индексом. Списки в Python имеют нулевую индексацию, как у массивов в других языках. Это означает, что первый элемент списка имеет индекс 0, второй элемент — индекс 1, третий — 2 и т. д.
Если запросить элемент по индексу за пределами списка, Python выкинет исключение .
Отрицательные индексы интерпретируются как подсчёт с конца списка.
То же действие можно воспроизвести следующим образом:
Списки в Python поддерживают слайсинг. Синтаксис слайса: . Результатом слайса будет новый список, содержащий элементы от начала до конца — 1.
Слайсингом можно развернуть список в обратную сторону:
Использование отрицательного шага эквивалентно следующему коду:
Дополнительные заметки о сортировке в Python
Перед завершением статьи давайте рассмотрим, что говорит документация Python о сортировке:
Как видите, в официальной документации утверждается, что уже и так было доказано: немного эффективнее. Кроме того, в документации говорится о том, что зачастую намного удобнее.
Может возникнуть вопрос касательно того, являются ли обе техники стабильные. К счастью, в документации есть ответ и на это:
Также верно при использовании реверсивного параметра или применении реверсивной функции дважды.
Заключение
После проведения небольшого анализа мы доказали, что немного быстрее и потребляет на 24% меньше памяти. Однако, стоит иметь в виду, что имплементируется только для списков, в то время как принимает любые итерации. Кроме того, при использовании вы потеряете оригинальный список.
Алгоритм быстрой сортировки
Этот алгоритм также использует разделяй и стратегию завоюйте, но использует подход сверху вниз вместо первого разделения массива вокруг шарнирного элемента (здесь, мы всегда выбираем последний элемент массива будут стержень).
Таким образом гарантируется, что после каждого шага точка поворота находится в назначенной позиции в окончательном отсортированном массиве.
Убедившись, что массив разделен вокруг оси поворота (элементы, меньшие точки поворота, находятся слева, а элементы, которые больше оси поворота, находятся справа), мы продолжаем применять функцию к остальной части, пока все элементы находятся в соответствующих позициях, когда массив полностью отсортирован.
def quicksort(a, arr_type):
def do_partition(a, arr_type, start, end):
# Performs the partitioning of the subarray a
# We choose the last element as the pivot
pivot_idx = end
pivot = a
# Keep an index for the first partition
# subarray (elements lesser than the pivot element)
idx = start - 1
def increment_and_swap(j):
nonlocal idx
idx += 1
a, a = a, a
< pivot]
# Finally, we need to swap the pivot (a with a)
# since we have reached the position of the pivot in the actual
# sorted array
a, a = a, a
# Return the final updated position of the pivot
# after partitioning
return idx+1
def quicksort_helper(a, arr_type, start, end):
if start < end:
# Do the partitioning first and then go via
# a top down divide and conquer, as opposed
# to the bottom up mergesort
pivot_idx = do_partition(a, arr_type, start, end)
quicksort_helper(a, arr_type, start, pivot_idx-1)
quicksort_helper(a, arr_type, pivot_idx+1, end)
quicksort_helper(a, arr_type, 0, len(a)-1)
Здесь метод выполняет шаг подхода Divide and Conquer, в то время метод разделяет массив вокруг точки поворота и возвращает позицию точки поворота, вокруг которой мы продолжаем рекурсивно разбивать подмассив до и после точки поворота, пока не будет весь массив отсортирован.
Прецедент:
b = array.array('i', )
print('Before QuickSort ->', b)
quicksort(b, 'i')
print('After QuickSort ->', b)
Вывод:
Before QuickSort -> array('i', )
After QuickSort -> array('i', )
2 Срезы
2.1 Синтаксис среза
Особенности среза:
Отрицательные значения старта и стопа означают, что считать надо не с начала, а с конца коллекции.
Отрицательное значение шага — перебор ведём в обратном порядке справа налево.
Если не указан старт — начинаем с самого края коллекции, то есть с первого элемента (включая его), если шаг положительный или с последнего (включая его), если шаг отрицательный (и соответственно перебор идет от конца к началу).
Если не указан стоп — идем до самого края коллекции, то есть до последнего элемента (включая его), если шаг положительный или до первого элемента (включая его), если шаг отрицательный (и соответственно перебор идет от конца к началу).
step = 1, то есть последовательный перебор слева направо указывать не обязательно — это значение шага по умолчанию
В таком случае достаточно указать
Можно сделать даже так — это значит взять коллекцию целиком
ВАЖНО: При срезе, первый индекс входит в выборку, а второй нет!
То есть от старта включительно, до стопа, где стоп не включается в результат. Математически это можно было бы записать как не идентично mylist, так как в первом случае мы включим все элементы, а во втором дойдем до 0 индекса, но не включим его!
2.3 Изменение списка срезом
Проиллюстрируем это на примерах ниже:
- Даже если хотим добавить один элемент, необходимо передавать итерируемый объект, иначе будет ошибка TypeError: can only assign an iterable
- Для вставки одиночных элементов можно использовать срез, код примеров есть ниже, но делать так не рекомендую, так как такой синтаксис хуже читать. Лучше использовать методы списка .append() и .insert():
- Можно менять части последовательности — это применение выглядит наиболее интересным, так как решает задачу просто и наглядно.
- Можно просто удалить часть последовательности
Примечание4 статья цикла
Maintaining Sort Order
Python does not provide modules like C++’s set and map data types as part of its standard library. This is a concious decision on the part of Guido, et al to preserve «one obvious way to do it.» Instead Python delegates this task to third-party libraries that are available on the Python Package Index. These libraries use various techniques to maintain list, dict, and set types in sorted order. Maintaining order using a specialized data structure can avoid very slow behavior (quadratic run-time) in the naive approach of editing and constantly re-sorting. Several implementations are described here.
-
Python SortedContainers Module — Pure-Python implementation that is fast-as-C implementations. Implements sorted list, dict, and set data types. Testing includes 100% code coverage and hours of stress. Documentation includes full API reference, performance comparison, and contributing/development guidelines.
-
Python rbtree Module — Provides a fast, C-implementation for dict and set data types. Based on a red-black tree implementation.
-
Python treap Module — Provides a sorted dict data type. Uses a treap for implementation and improves performance using Cython.
-
Python bintrees Module — Provides several tree-based implementations for dict and set data types. Fastest implementations are based on AVL and Red-Black trees. Implemented in C. Extends the conventional API to provide set operations for dict data types.
-
Python banyan Module — Provides a fast, C-implementation for dict and set data types.
-
Python skiplistcollections Module — Pure-Python implementation based on skip-lists providing a limited API for dict and set data types.
-
Python blist Module — Provides sorted list, dict and set data types based on the «blist» data type, a B-tree implementation. Implemented in Python and C.
Что такое списки?
Списки в Python — упорядоченные изменяемые коллекции объектов произвольных типов (почти как массив, но типы могут отличаться).
Чтобы использовать списки, их нужно создать. Создать список можно несколькими способами. Например, можно обработать любой итерируемый объект (например, строку) встроенной функцией list:
>>> list('список')
Список можно создать и при помощи литерала:
>>> s = [] # Пустой список >>> l = 's', 'p', 'isok'], 2 >>> s [] >>> l , 2]
Как видно из примера, список может содержать любое количество любых объектов (в том числе и вложенные списки), или не содержать ничего.
И еще один способ создать список — это генераторы списков. Генератор списков — способ построить новый список, применяя выражение к каждому элементу последовательности. Генераторы списков очень похожи на цикл for.
>>> c = c * 3 for c in 'list' >>> c
Возможна и более сложная конструкция генератора списков:
>>> c = c * 3 for c in 'list' if c != 'i' >>> c >>> c = c + d for c in 'list' if c != 'i' for d in 'spam' if d != 'a' >>> c
Встроенные функции сортировки на Python
Иногда полезно знать перечисленные выше алгоритмы, но в большинстве случаев разработчик, скорее всего, будет использовать функции сортировки, уже предоставленные в языке программирования.
Отсортировать содержимое списка можно с помощью стандартного метода :
Или можно использовать функцию для создания нового отсортированного списка, оставив входной список нетронутым:
Оба эти метода сортируют в порядке возрастания, но можно изменить порядок, установив для флага значение :
В отличие от других алгоритмов, обе функции в Python могут сортировать также списки кортежей и классов. Функция может сортировать любую последовательность, которая включает списки, строки, кортежи, словари, наборы и пользовательские итераторы, которые вы можете создать.
Функции в Python реализуют алгоритм Tim Sort, основанный на сортировке слиянием и сортировке вставкой.
Методы списков
Давайте теперь
предположим, что у нас имеется список из чисел:
a = 1, -54, 3, 23, 43, -45,
и мы хотим в
конец этого списка добавить значение. Это можно сделать с помощью метода:
a.append(100)
И обратите
внимание: метод append ничего не возвращает, то есть, он меняет
сам список благодаря тому, что он относится к изменяемому типу данных. Поэтому
писать здесь конструкцию типа
a = a.append(100)
категорически не
следует, так мы только потеряем весь наш список! И этим методы списков
отличаются от методов строк, когда мы записывали:
string="Hello" string = string.upper()
Здесь метод upper возвращает
измененную строку, поэтому все работает как и ожидается. А метод append ничего не
возвращает, и присваивать значение None переменной a не имеет
смысла, тем более, что все работает и так:
a = 1, -54, 3, 23, 43, -45, a.append(100)
Причем, мы в методе
append можем записать
не только число, но и другой тип данных, например, строку:
a.append("hello")
тогда в конец
списка будет добавлен этот элемент. Или, булевое значение:
a.append(True)
Или еще один
список:
a.append(1,2,3)
И так далее. Главное,
чтобы было указано одно конкретное значение. Вот так работать не будет:
a.append(1,2)
Если нам нужно
вставить элемент в произвольную позицию, то используется метод
a.insert(3, -1000)
Здесь мы
указываем индекс вставляемого элемента и далее значение самого элемента.
Следующий метод remove удаляет элемент
по значению:
a.remove(True)
a.remove('hello')
Он находит
первый подходящий элемент и удаляет его, остальные не трогает. Если же
указывается несуществующий элемент:
a.remove('hello2')
то возникает
ошибка. Еще один метод для удаления
a.pop()
выполняет
удаление последнего элемента и при этом, возвращает его значение. В самом
списке последний элемент пропадает. То есть, с помощью этого метода можно
сохранять удаленный элемент в какой-либо переменной:
end = a.pop()
Также в этом
методе можно указывать индекс удаляемого элемента, например:
a.pop(3)
Если нам нужно
очистить весь список – удалить все элементы, то можно воспользоваться методом:
a.clear()
Получим пустой
список. Следующий метод
a = 1, -54, 3, 23, 43, -45, c = a.copy()
возвращает копию
списка. Это эквивалентно конструкции:
c = list(a)
В этом можно
убедиться так:
c1 = 1
и список c будет отличаться
от списка a.
Следующий метод count позволяет найти
число элементов с указанным значением:
c.count(1) c.count(-45)
Если же нам
нужен индекс определенного значения, то для этого используется метод index:
c.index(-45) c.index(1)
возвратит 0,
т.к. берется индекс только первого найденного элемента. Но, мы здесь можем
указать стартовое значение для поиска:
c.index(1, 1)
Здесь поиск
будет начинаться с индекса 1, то есть, со второго элемента. Или, так:
c.index(23, 1, 5)
Ищем число 23 с
1-го индекса и по 5-й не включая его. Если элемент не находится
c.index(23, 1, 3)
то метод
приводит к ошибке. Чтобы этого избежать в своих программах, можно вначале
проверить: существует ли такой элемент в нашем срезе:
23 in c1:3
и при значении True далее уже
определять индекс этого элемента.
Следующий метод
c.reverse()
меняет порядок
следования элементов на обратный.
Последний метод,
который мы рассмотрим, это
c.sort()
выполняет
сортировку элементов списка по возрастанию. Для сортировки по убыванию, следует
этот метод записать так:
c.sort(reverse=True)
Причем, этот
метод работает и со строками:
lst = "Москва", "Санкт-Петербург", "Тверь", "Казань" lst.sort()
Здесь
используется лексикографическое сравнение, о котором мы говорили, когда
рассматривали строки.
Это все основные
методы списков и чтобы вам было проще ориентироваться, приведу следующую
таблицу:
|
Метод |
Описание |
|
append() |
Добавляет |
|
insert() |
Вставляет |
|
remove() |
Удаляет |
|
pop() |
Удаляет |
|
clear() |
Очищает |
|
copy() |
Возвращает |
|
count() |
Возвращает |
|
index() |
Возвращает |
|
reverse() |
Меняет |
|
sort() |
Сортирует |
Реализация
Сортировка массивов
Быстрая сортировка является естественным рекурсивным алгоритмом — разделите входной массив на меньшие массивы, переместите элементы в нужную сторону оси и повторите.
При этом мы будем использовать две функции — partition() и quick_sort().
Давайте начнем с функции partition():
def partition(array, begin, end):
pivot = begin
for i in xrange(begin+1, end+1):
if array <= array:
pivot += 1
array, array = array, array
array, array = array, array
return pivot
И, наконец, давайте реализуем функцию quick_sort():
def quick_sort(array, begin=0, end=None):
if end is None:
end = len(array) - 1
def _quicksort(array, begin, end):
if begin >= end:
return
pivot = partition(array, begin, end)
_quicksort(array, begin, pivot-1)
_quicksort(array, pivot+1, end)
return _quicksort(array, begin, end)
После того, как обе функции реализованы, мы можем запустить quick_sort():
array = quick_sort(array) print(array)
Результат:
Поскольку алгоритм unstable (нестабилен), нет никакой гарантии, что два 19 будут всегда в этом порядке друг за другом. Хотя это ничего не значит для массива целых чисел.
Оптимизация быстрой сортировки
Учитывая, что быстрая сортировка сортирует «половинки» заданного массива независимо друг от друга, это оказывается очень удобным для распараллеливания. У нас может быть отдельный поток, который сортирует каждую «половину» массива, и в идеале мы могли бы вдвое сократить время, необходимое для его сортировки.
Однако быстрая сортировка может иметь очень глубокий рекурсивный стек вызовов, если нам особенно не повезло в выборе опорного элемента, а распараллеливание будет не так эффективно, как в случае сортировки слиянием.
Для сортировки небольших массивов рекомендуется использовать простой нерекурсивный алгоритм. Даже что-то простое, например сортировка вставкой, будет более эффективным для небольших массивов, чем быстрая сортировка. Поэтому в идеале мы могли бы проверить, имеет ли наш подмассив лишь небольшое количество элементов (большинство рекомендаций говорят о 10 или менее значений), и если да, то мы бы отсортировали его с помощью Insertion Sort (сортировка вставкой).
Key Functions
Starting with Python 2.4, both list.sort() and sorted() added a key parameter to specify a function to be called on each list element prior to making comparisons.
For example, here’s a case-insensitive string comparison:
>>> sorted("This is a test string from Andrew".split(), key=str.lower)
The value of the key parameter should be a function that takes a single argument and returns a key to use for sorting purposes. This technique is fast because the key function is called exactly once for each input record.
A common pattern is to sort complex objects using some of the object’s indices as a key. For example:
>>> student_tuples = >>> sorted(student_tuples, key=lambda student: student) # sort by age
The same technique works for objects with named attributes. For example:
>>> class Student:
def __init__(self, name, grade, age):
self.name = name
self.grade = grade
self.age = age
def __repr__(self):
return repr((self.name, self.grade, self.age))
def weighted_grade(self):
return 'CBA'.index(self.grade) / float(self.age)
>>> student_objects =
>>> sorted(student_objects, key=lambda student: student.age) # sort by age
Sorting a List of Strings
So what if you want to sort a list of strings instead of numbers?
Well, nothing really changes.
You can still use sort or sorted.
Here is an example using sort:
and you can still use the reverse parameter to sort in a descending order.
Let’s look at another example, this time using sorted
So far so good, but there is a catch.
Let’s see what happens when there exists uppercase letters.
That’s interesting. Bananas appears before apples
The reason for that is because Python treats all uppercase letters to be lower than lowercase letters.
If that’s what you want then cool, go ahead and use it without any modifications.
However, most of the time you want to treat strings as case insensitive when it comes to sorting.
So how can you sort a list of strings in a case insensitive manner?
Starting with Python 2.4, both sort and sorted added an optional key parameter.
This key parameter specifies a function that will be called on each list item before making comparisons.
This is indeed very helpful because now we can pass the str.lower as the key parameter to the sort function.
And this will instruct the sort function to perform comparisons between the all-lowercase versions of the strings which is exactly what we want!
As you can see, now the sorting is case insensitive.
In fact the key parameter is very powerful as it allows us to define our own custom sorting functions as we will see later.
Задания для самоподготовки
1. Пользователь
вводит с клавиатуры числа, до тех пор, пока не введет число 0. На основе
введенных данных нужно сформировать список, состоящий из квадратов введенных
чисел.
2. Написать
программу удаления из списка
всех номеров с
кодом «+7».
3. Написать
программу циклического сдвига элементов списка влево. Например, дан список:
после сдвига на
один элемент влево, должны получить:
Реализовать
через цикл, перебирая все элементы.
4. Написать
аналогичную программу циклического сдвига, но теперь вправо.
Видео по теме
Python 3 #1: установка и запуск интерпретатора языка
Python 3 #2: переменные, оператор присваивания, типы данных
Python 3 #3: функции input и print ввода/вывода
Python 3 #4: арифметические операторы: сложение, вычитание, умножение, деление, степень
Python 3 #5: условный оператор if, составные условия с and, or, not
Python 3 #6: операторы циклов while и for, операторы break и continue
Python 3 #7: строки — сравнения, срезы строк, базовые функции str, len, ord, in
Python 3 #8: методы строк — upper, split, join, find, strip, isalpha, isdigit и другие
Python 3 #9: списки list и функции len, min, max, sum, sorted
Python 3 #10: списки — срезы и методы: append, insert, pop, sort, index, count, reverse, clear
Python 3 #11: списки — инструмент list comprehensions, сортировка методом выбора
Python 3 #12: словарь, методы словарей: len, clear, get, setdefault, pop
Python 3 #13: кортежи (tuple) и операции с ними: len, del, count, index
Python 3 #14: функции (def) — объявление и вызов
Python 3 #15: делаем «Сапер», проектирование программ «сверху-вниз»
Python 3 #16: рекурсивные и лямбда-функции, функции с произвольным числом аргументов
Python 3 #17: алгоритм Евклида, принцип тестирования программ
Python 3 #18: области видимости переменных — global, nonlocal
Python 3 #19: множества (set) и операции над ними: вычитание, пересечение, объединение, сравнение
Python 3 #20: итераторы, выражения-генераторы, функции-генераторы, оператор yield
Python 3 #21: функции map, filter, zip
Python 3 #22: сортировка sort() и sorted(), сортировка по ключам
Python 3 #23: обработка исключений: try, except, finally, else
Python 3 #24: файлы — чтение и запись: open, read, write, seek, readline, dump, load, pickle
Python 3 #25: форматирование строк: метод format и F-строки
Python 3 #26: создание и импорт модулей — import, from, as, dir, reload
Python 3 #27: пакеты (package) — создание, импорт, установка (менеджер pip)
Python 3 #28: декораторы функций и замыкания
Python 3 #29: установка и порядок работы в PyCharm
Python 3 #30: функция enumerate, примеры использования
Обзор возможностей программы
Ace Stream – это не просто посредник, который позволяет воспроизводить торренты. Программа работает как самостоятельный видеоплеер, достаточно удобный и функциональный. При этом при просмотре торрентов владелец может контролировать процесс загрузки, устанавливать желаемые параметры.
Как скачать Acestream на разных устройствах
Важно помнить, что для установки программы необходимо дополнительное устройство с подключением к Интернету. Чаще всего используются компьютер или планшет
Также подойдет телефон. Непосредственно на Smart TV виджет не устанавливается.
Установка на ПК
Для установки Ace Stream на компьютер потребуется скачать последнюю версию на официальном сайте. Затем выполняются следующие действия:
Запустить установку программы. При установке отметить пункт «Запускать вместе с Windows».
В антивирусной программе отключить файервол, чтобы он не блокировал доступ ТВ к AceStream.
Зайти в Ace Stream Media Centre.
Открыть «Сетевые подключения». Записать или запомнить IP адрес
Это важно, поскольку Smart TV и ПК должны находится в одной сети.
Важно! При установке программы на компьютер следует выставить диск для Кэша с большим объемом памяти, поскольку при просмотре отельных торрентов необходимо большое хранилище
Установка Acestream на Android
Процедура установки на Андроид мало чем отличается от описанной выше. Алгоритм действий следующий:
- Зайти на официальный веб-сайт и загрузить Ace Player.
- Выполнить установку приложения на устройство с Android.
- Открыть программу.
- В верхнем углу справа кликнуть на «Меню» и ввести идентификатор контента в специальном поле.
- Кликнуть на значок Acestream для открытия приложения.
Установка на ТВ
AceStream не предназначен для установки непосредственно на телевизор. Для правильного функционирования приложение должно быть запущено с телевизора, смартфона или планшета, а на Smart TV должен присутствовать виджет Forkplayer.
Параметр key
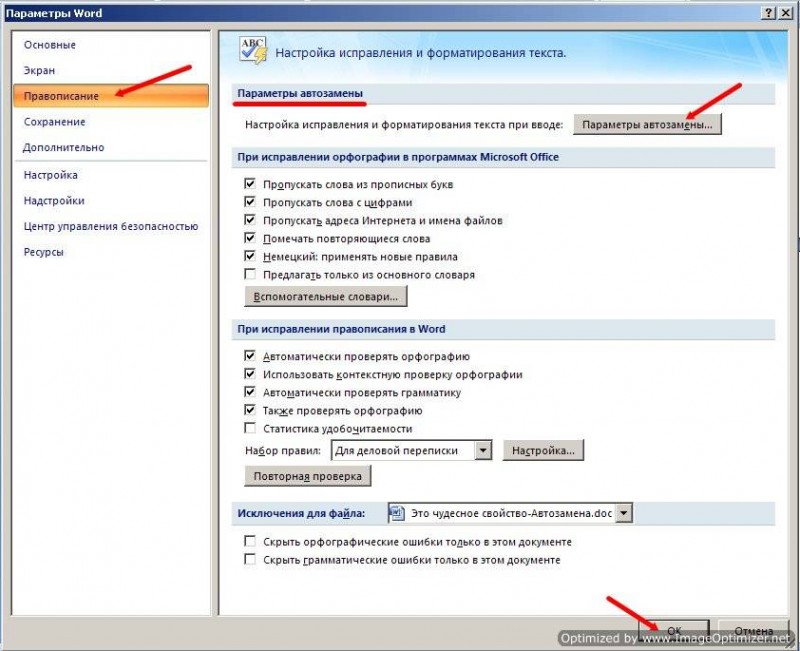
Функций и sorted() содержат параметр key чтобы указать функцию вызываемую для каждого аргумента перед сравнением.
Пример регистронезависимого сравнения:
>>> sorted(«This is a test string from Andrew».split(), key=str.lower)
|
1 |
>>>sorted(«This is a test string from Andrew».split(),key=str.lower) ‘a’,’Andrew’,’from’,’is’,’string’,’test’,’This’ |
Функция передаваемая в key содержит один аргумент и возвращает ключ используемый для сортировки. Это эффективный подход, так как функция вызывается ровно один раз для каждого элемента.
Общий шаблон для отсортировки сложных объектов — использование одного из индексов как ключа:
>>> student_tuples =
>>> sorted(student_tuples, key=lambda student: student) # сортировка по возрасту
|
1 |
>>>student_tuples= …(‘john’,’A’,15), …(‘jane’,’B’,12), …(‘dave’,’B’,10), >>>sorted(student_tuples,key=lambda studentstudent2)# сортировка по возрасту (‘dave’,’B’,10),(‘jane’,’B’,12),(‘john’,’A’,15) |
Тот же способ работает для объектов с именованными атрибутам:
>>> class Student:
… def __init__(self, name, grade, age):
… self.name = name
… self.grade = grade
… self.age = age
… def __repr__(self):
… return repr((self.name, self.grade, self.age))
|
1 |
>>>classStudent …def __init__(self,name,grade,age) …self.name=name …self.grade=grade …self.age=age …def __repr__(self) …returnrepr((self.name,self.grade,self.age)) |
>>> student_objects =
>>> sorted(student_objects, key=lambda student: student.age) # сортировка по возрасту
|
1 |
>>>student_objects= …Student(‘john’,’A’,15), …Student(‘jane’,’B’,12), …Student(‘dave’,’B’,10), >>>sorted(student_objects,key=lambda studentstudent.age)# сортировка по возрасту (‘dave’,’B’,10),(‘jane’,’B’,12),(‘john’,’A’,15) |
The Old Way Using Decorate-Sort-Undecorate
This idiom is called Decorate-Sort-Undecorate after its three steps:
- First, the initial list is decorated with new values that control the sort order.
- Second, the decorated list is sorted.
- Finally, the decorations are removed, creating a list that contains only the initial values in the new order.
For example, to sort the student data by grade using the DSU approach:
>>> decorated = >>> decorated.sort() >>> # undecorate
This idiom works because tuples are compared lexicographically; the first items are compared; if they are the same then the second items are compared, and so on.
It is not strictly necessary in all cases to include the index i in the decorated list. Including it gives two benefits:
- The sort is stable — if two items have the same key, their order will be preserved in the sorted list.
-
The original items do not have to be comparable because the ordering of the decorated tuples will be determined by at most the first two items. So for example the original list could contain complex numbers which cannot be sorted directly.
Another name for this idiom is Schwartzian transform, after Randal L. Schwartz, who popularized it among Perl programmers.
For large lists and lists where the comparison information is expensive to calculate, and Python versions before 2.4, DSU is likely to be the fastest way to sort the list. For 2.4 and later, key functions provide the same functionality.
Входные данные не меняются
Пусть есть два списка и .
Начнем с самого простого алгоритма: обозначим метки за и и будем брать меньший из , и увеличивать его метку на единицу, пока одна из меток не выйдет за границу списка.
При первом сравнении мы выберем минимальный элемент из двух минимальных в своем списке и подвинемся на следующий элемент, поэтому наименьший элемент из двух списков будет стоять на нулевом месте результирующего. Дальше несложно по индукции доказать, что далее слияние пройдет верно.
Перейдем к коду:
Заметим, что в данном коде используется только перемещение вперед по списку. Поэтому будет достаточно работать с итераторами. Перепишем алгоритм с помощью итераторов.
Еще изменим обработку концов списков, так как теперь мы не умеем копировать сразу до конца. Будем обрабатывать элементы до того, когда оба итератора дойдут до конца, при этом, если один уже оказался в конце, будем просто брать из второго.
В этой реализации можно вместо добавления по одному элементу () собрать генератор, а потом из него получить список. Для этого напишем отдельную функцию, которая будет строить генератор, а основная функция сделает из него список.
Встроенные реализации
Рассмотрим еще несколько способов слияния через встроенные в python функции.
-
из . Как говорит документация, эта функция делает именно то, что мы хотим, и больше: объединяет несколько итерируемых объекта, можно задать ключ, можно сортировать в обратном порядке.
Тогда нам нужно просто импортировать и использовать:
-
из . умеет считать количество вхождений каждого из элементов, выдавать их в тех количествах, в которых они входят, и еще несколько полезных вещей, которые сейчас не нужны (например, несколько самых часто встречающихся элементов).
Воспользуемся для слияния элементов и :
-
И, наконец, просто сортировка. Объединяем и сортируем заново.