Регулярные выражения
Содержание:
- Введение в регулярные выражения
- Регулярные выражения и Unicode¶
- Опережающая проверка
- Клей из пенопласта и растворителя своими руками
- Брокер — это не навсегда. Не понравится — найдете другого
- Операторы контроля
- Замена текста REGEXP_REPLACE
- regexp.test(str)
- Проверка наличия совпадения
- Строковые методы, поиск и замена
- str.replace(str|regexp, str|func)
- Примеры шаблонов
- Количество {n}
- Жадность¶
- Группировка в регулярных выражениях
- Заключение
Введение в регулярные выражения
Язык регулярных выражений предназначен специально для обработки строк. Он включает два средства:
-
Набор управляющих кодов для идентификации специфических типов символов
-
Система для группирования частей подстрок и промежуточных результатов таких действий
С помощью регулярных выражений можно выполнять достаточно сложные и высокоуровневые действия над строками:
-
Идентифицировать (и возможно, помечать к удалению) все повторяющиеся слова в строке
-
Сделать заглавными первые буквы всех слов
-
Преобразовать первые буквы всех слов длиннее трех символов в заглавные
-
Обеспечить правильную капитализацию предложений
-
Выделить различные элементы в URI (например, имея http://www.professorweb.ru, выделить протокол, имя компьютера, имя файла и т.д.)
Главным преимуществом регулярных выражений является использование метасимволов — специальные символы, задающие команды, а также управляющие последовательности, которые работают подобно управляющим последовательностям C#. Это символы, предваренные знаком обратного слеша (\) и имеющие специальное назначение.
В следующей таблице специальные метасимволы регулярных выражений C# сгруппированы по смыслу:
Метасимволы, используемые в регулярных выражениях C#
Символ
Значение
Пример
Соответствует
Классы символов
Любой из символов, указанных в скобках
В исходной строке может быть любой символ английского алфавита в нижнем регистре
Любой из символов, не указанных в скобках
В исходной строке может быть любой символ кроме цифр
.
Любой символ, кроме перевода строки или другого разделителя Unicode-строки
\w
Любой текстовый символ, не являющийся пробелом, символом табуляции и т.п.
\W
Любой символ, не являющийся текстовым символом
\s
Любой пробельный символ из набора Unicode
\S
Любой непробельный символ из набора Unicode
Обратите внимание, что символы \w и \S — это не одно и то же
\d
Любые ASCII-цифры. Эквивалентно
\D
Любой символ, отличный от ASCII-цифр
Эквивалентно
Символы повторения
{n,m}
Соответствует предшествующему шаблону, повторенному не менее n и не более m раз
s{2,4}
«Press», «ssl», «progressss»
{n,}
Соответствует предшествующему шаблону, повторенному n или более раз
s{1,}
«ssl»
{n}
Соответствует в точности n экземплярам предшествующего шаблона
s{2}
«Press», «ssl», но не «progressss»
?
Соответствует нулю или одному экземпляру предшествующего шаблона; предшествующий шаблон является необязательным
Эквивалентно {0,1}
+
Соответствует одному или более экземплярам предшествующего шаблона
Эквивалентно {1,}
*
Соответствует нулю или более экземплярам предшествующего шаблона
Эквивалентно {0,}
Символы регулярных выражений выбора
|
Соответствует либо подвыражению слева, либо подвыражению справа (аналог логической операции ИЛИ).
(…)
Группировка. Группирует элементы в единое целое, которое может использоваться с символами *, +, ?, | и т.п. Также запоминает символы, соответствующие этой группе для использования в последующих ссылках.
(?:…)
Только группировка. Группирует элементы в единое целое, но не запоминает символы, соответствующие этой группе.
Якорные символы регулярных выражений
^
Соответствует началу строкового выражения или началу строки при многострочном поиске.
^Hello
«Hello, world», но не «Ok, Hello world» т.к. в этой строке слово «Hello» находится не в начале
$
Соответствует концу строкового выражения или концу строки при многострочном поиске.
Hello$
«World, Hello»
\b
Соответствует границе слова, т.е. соответствует позиции между символом \w и символом \W или между символом \w и началом или концом строки.
\b(my)\b
В строке «Hello my world» выберет слово «my»
\B
Соответствует позиции, не являющейся границей слов.
\B(ld)\b
Соответствие найдется в слове «World», но не в слове «ld»
Регулярные выражения и Unicode¶
Флаг является обязательным при работе с Unicode строками, в частности когда может понадобится обрабатывать строки в астральных плоскостях, которые не включены в первые 1600 символов Unicode.
Например эмодзи, но и только они.
Если вы не добавили этот флаг, то это просто регулярное выражение, которые должно найти совпадение одного символа, не будет работать, потому что для JavaScript этот эмодзи внутри представлен двумя символами:
Поэтому, всегда используйте флаг .
Unicode, как и обычные символы, может обрабатывать диапазоны:
JavaScript проверяет внутренние коды представления, поэтому на самом деле . Посмотрите полный список эмодзи чтобы увидеть коды и узнать их порядок.
Опережающая проверка
Синтаксис опережающей проверки: .
Он означает: найди при условии, что за ним следует . Вместо и здесь может быть любой шаблон.
Для целого числа, за которым идёт знак , шаблон регулярного выражения будет :
Обратим внимание, что проверка – это именно проверка, содержимое скобок не включается в результат. При поиске движок регулярных выражений, найдя , проверяет есть ли после него
Если это не так, то игнорирует совпадение и продолжает поиск дальше
При поиске движок регулярных выражений, найдя , проверяет есть ли после него . Если это не так, то игнорирует совпадение и продолжает поиск дальше.
Возможны и более сложные проверки, например означает:
- Найти .
- Проверить, идёт ли сразу после (если нет – не подходит).
- Проверить, идёт ли сразу после (если нет – не подходит).
- Если обе проверки прошли – совпадение найдено.
То есть, этот шаблон означает, что мы ищем при условии, что за ним идёт и и .
Такое возможно только при условии, что шаблоны и не являются взаимно исключающими.
Например, ищет при условии, что за ним идёт пробел, и где-то впереди есть :
В нашей строке это как раз число .
Клей из пенопласта и растворителя своими руками
Первый вариант получения клеевого раствора заключается в растворении кусков пенопласта в разбавителе. Разбавителем можно использовать бензин. Способов изготовления клеевого раствора несколько, различие в основном в видах материалов, которые будут использоваться, как компоненты состава.
Подобный клей из пенопласта своими руками позволяет получить прочное соединение при ремонтных работах на крыше, возможно применения как соединяющего вещества стыковочных мест во время кровельных работ. Высохнув состав становиться похож на стекло.
Второй метод создания пенопластового вещества для склеивания материалов, заключается в распределение мелких частей пенопласта по месту, где нужно склеить детали, после этого пенопластовые части поливаются растворителем, в итоге части начинают растворяться, материал заполняет все трещинки и равномерно закрывает имеющиеся зазоры.
Подобный клей из пенопласта своими руками позволяет получить прочное соединение при ремонтных работах.
Особенности самодельного клея, где может применяться
Прежде, чем растворить пенопласт до жидкого состояния, нужно изучить особенности работы с компонентами, иначе можно получить неудовлетворительный результат. Отмечают следующие правила:
- Работать необходимо, соблюдая меры безопасности, чтобы не получить проблем со здоровьем;
- Нельзя заниматься изготовлением и поклейкой вблизи открытых источников огня, вещества воспламеняющиеся, поэтому подобное соседство опасно;
- Получившееся средство следует хорошо размешивать, чтобы клеевые характеристики получились надежными;
- Средство может применяться, как защитное покрытие, тогда готовят более жидкий раствор;
- Отвердение покрытия происходит через несколько дней, количество их зависит от толщины слоя.
В бытовых условиях состав может использоваться для разных целей. Среди них выделяются склеивание карнизов на потолке, фиксация половых плинтусов, ремонта различных деталей мебели, установка экструдированного пенополистирола. Может применяться вместо казеинового и столярного клеевого раствора. Получившийся шов сохраняет свои свойства около полутора лет.
Получившееся средство следует хорошо размешивать, чтобы клеевые характеристики получились надежными.
Брокер — это не навсегда. Не понравится — найдете другого
Операторы контроля
Ещё один вид специальных символов — это операторы контроля. Такие символы позволяют описывать шаблоны с границами, то есть указывать, где начинается или заканчивается слово или строка. С помощью операторов контроля также можно создавать более сложные шаблоны, такие как опережающие проверки, ретроспективные проверки и условные выражения.
/* Оператор контроля - Значение */^ - начало строки (последующее регулярное выражение должно совпадать с началом проверяемой строки).$ - конец строки (последующее регулярное выражение должно совпадать с концом проверяемой строки).\b - граница слова, то есть его начало или конец.\B - несловообразующая граница.x(?=y) - опережающая проверка. Совпадение с "x", только если за "x" следует "y".x(?!y) - негативная опережающая проверка. Совпадение с "x", только если за "x" не следует "y".(?<=y)x - ретроспективная проверка. Совпадение с "x", только если перед "x" стоит "y".(?<!y)x - негативная ретроспективная проверка. Совпадение с "x", только если перед "x" не стоит "y".
Примеры:
// ^ - Начало строкиconst myPattern = /^re/console.log(myPattern.test('write'))// falseconsole.log(myPattern.test('read'))// trueconsole.log(myPattern.test('real'))// trueconsole.log(myPattern.test('free'))// false// $ - Конец строкиconst myPattern = /ne$/console.log(myPattern.test('all is done'))// trueconsole.log(myPattern.test('on the phone'))// trueconsole.log(myPattern.test('in Rome'))// falseconsole.log(myPattern.test('Buy toner'))// false// \b - Граница словаconst myPattern = /\bro/console.log(myPattern.test('road'))// trueconsole.log(myPattern.test('steep'))// falseconsole.log(myPattern.test('umbro'))// false// Илиconst myPattern = /\btea\b/console.log(myPattern.test('tea'))// trueconsole.log(myPattern.test('steap'))// falseconsole.log(myPattern.test('tear'))// false// \B - Несловообразующая границаconst myPattern = /\Btea\B/console.log(myPattern.test('tea'))// falseconsole.log(myPattern.test('steap'))// trueconsole.log(myPattern.test('tear'))// false// x(?=y) - Опережающая проверкаconst myPattern = /doo(?=dle)/console.log(myPattern.test('poodle'))// falseconsole.log(myPattern.test('doodle'))// trueconsole.log(myPattern.test('moodle'))// false// x(?!y) - Негативная опережающая проверкаconst myPattern = /gl(?!u)/console.log(myPattern.test('glue'))// falseconsole.log(myPattern.test('gleam'))// true// (?<=y)x - Ретроспективная проверкаconst myPattern = /(?<=re)a/console.log(myPattern.test('realm'))// trueconsole.log(myPattern.test('read'))// trueconsole.log(myPattern.test('rest'))// false// (?<!y)x - Негативная ретроспективная проверкаconst myPattern = /(?<!re)a/console.log(myPattern.test('break'))// falseconsole.log(myPattern.test('treat'))// falseconsole.log(myPattern.test('take'))// true
Замена текста REGEXP_REPLACE
Поиск и замена — одна из лучших областей применения регулярных выражений. Текст замены может включать ссылки на части исходного выражения (называемые обратными ссылками), открывающие чрезвычайно мощные возможности при работе с текстом. Допустим, имеется список имен, разделенный запятыми, и его содержимое необходимо вывести по два имени в строке. Одно из решений заключается в том, чтобы заменить каждую вторую запятую символом новой строки. Сделать это при помощи стандартной функции нелегко, но с функцией задача решается просто. Общий синтаксис ее вызова:
REGEXP_REPLACE (исходная_строка, шаблон ]])
Здесь исходная_строка — строка, в которой выполняется поиск; шаблон — регулярное выражение, совпадение которого ищется в исходной_строке; начальная_позиция — позиция, с которой начинается поиск; модификаторы — один или несколько модификаторов, управляющих процессом поиска. Пример:
DECLARE
names VARCHAR2(60) := 'Anna,Matt,Joe,Nathan,Andrew,Jeff,Aaron';
names_adjusted VARCHAR2(61);
comma_delimited BOOLEAN;
extracted_name VARCHAR2(60);
name_counter NUMBER;
BEGIN
-- Искать совпадение шаблона
comma_delimited := REGEXP_LIKE(names,'^(*,)+(*){1}$', 'i');
-- Продолжать, только если мы действительно
-- работаем со списком, разделенным запятыми.
IF comma_delimited THEN
names := REGEXP_REPLACE(
names,
'(*),(*),',
'\1,\2' || chr(10) );
END IF;
DBMS_OUTPUT.PUT_LINE(names);
END;
Результат выглядит так:
Anna,Matt Joe,Nathan Andrew,Jeff Aaron
При вызове функции передаются три аргумента:
- names — исходная строка;
- ‘(*),(*),’ — выражение, описывающее заменяемый текст (см. ниже);
- ‘\1,\2 ‘ || chr(10) — текст замены. \1 и \2 — обратные ссылки, заложенные в основу нашего решения. Подробные объяснения также приводятся ниже.
Выражение, описывающее искомый текст, состоит из двух подвыражений в круглых скобках и двух запятых.
- Совпадение должно начинаться с имени.
- За именем должна следовать запятая.
- Затем идет другое имя.
- И снова одна запятая.
Наша цель — заменить каждую вторую запятую символом новой строки. Вот почему выражение написано так, чтобы оно совпадало с двумя именами и двумя запятыми. Также запятые не напрасно выведены за пределы подвыражений.
Первое совпадение для нашего выражения, которое будет найдено при вызове , выглядит так:
Anna,Matt,
Два подвыражения соответствуют именам «» и «». В основе нашего решения лежит возможность ссылаться на текст, совпавший с заданным подвыражением, через обратную ссылку. Обратные ссылки и в тексте замены ссылаются на текст, совпавший с первым и вторым подвыражением. Вот что происходит:
'\1,\2' || chr(10) -- Текст замены
'Anna,\2' || chr(10) -- Подстановка текста, совпавшего
-- с первым подвыражением
'Anna,Matt' || chr(10) -- Подстановка текста, совпавшего
-- со вторым подвыражением
Вероятно, вы уже видите, какие мощные инструменты оказались в вашем распоряжении. Запятые из исходного текста попросту не используются. Мы берем текст, совпавший с двумя подвыражениями (имена «Anna» и «Matt»), и вставляем их в новую строку с одной запятой и одним символом новой строки.
Но и это еще не все! Текст замены легко изменить так, чтобы вместо запятой в нем использовался символ табуляции (ASCII-код 9):
names := REGEXP_REPLACE( names, '(*),(*),', '\1' || chr(9) || '\2' || chr(10) );
Теперь результаты выводятся в два аккуратных столбца:
Anna Matt Joe Nathan Andrew Jeff Aaron
Поиск и замена с использованием регулярных выражений — замечательная штука. Это мощный и элегантный механизм, с помощью которого можно сделать очень многое.
regexp.test(str)
The method looks for a match and returns whether it exists.
For instance:
An example with the negative answer:
If the regexp has flag , then looks from property and updates this property, just like .
So we can use it to search from a given position:
Same global regexp tested repeatedly on different sources may fail
If we apply the same global regexp to different inputs, it may lead to wrong result, because call advances property, so the search in another string may start from non-zero position.
For instance, here we call twice on the same text, and the second time fails:
That’s exactly because is non-zero in the second test.
To work around that, we can set before each search. Or instead of calling methods on regexp, use string methods , they don’t use .
Проверка наличия совпадения
Регулярные выражения используются для описания текста, который требуется найти в строке (и возможно, подвергнуть дополнительной обработке). Давайте вернемся к примеру, который приводился ранее в этом блоге:
DECLARE names VARCHAR2(60) := 'Anna,Matt,Joe,Nathan,Andrew,Aaron,Jeff';
Допустим, мы хотим определить на программном уровне, содержит ли строка список имен, разделенных запятыми. Для этого мы воспользуемся функцией , обнаруживающей совпадения шаблона в строке:
DECLARE
names VARCHAR2(60) := 'Anna,Matt,Joe,Nathan,Andrew,Jeff,Aaron';
names_adjusted VARCHAR2(61);
comma_delimited BOOLEAN;
BEGIN
--Поиск по шаблону
comma_delimited := REGEXP_LIKE(names,'^(*,)+(*){1}$');
--Вывод результата
DBMS_OUTPUT.PUT_LINE(
CASE comma_delimited
WHEN true THEN 'Обнаружен список с разделителями!'
ELSE 'Совпадение отсутствует.'
END);
END;
Результат:
Обнаружен список с разделителями
Чтобы разобраться в происходящем, необходимо начать с выражения, описывающего искомый текст. Общий синтаксис функции выглядит так:
REGEXP_LIKE (исходная_строка, шаблон )
Здесь — символьная строка, в которой ищутся совпадения; шаблон — регулярное выражение, совпадения которого ищутся в исходной_строке; модификаторы — один или несколько модификаторов, управляющих процессом поиска. Если функция находит совпадение шаблона в , она возвращает логическое значение ; в противном случае возвращается .
Процесс построения регулярного выражения выглядел примерно так:
- Каждый элемент списка имен может состоять только из букв и пробелов. Квадратные скобки определяют набор символов, которые могут входить в совпадение. Диапазон a–z описывает все буквы нижнего регистра, а диапазон A–Z — все буквы верхнего регистра. Пробел находится между двумя компонентами выражения. Таким образом, этот шаблон описывает один любой символ нижнего или верхнего регистра или пробел.
- * Звездочка является квантификатором — служебным символом, который указывает, что каждый элемент списка содержит ноль или более повторений совпадения, описанного шаблоном в квадратных скобках.
- *, Каждый элемент списка должен завершаться запятой. Последний элемент является исключением, но пока мы не будем обращать внимания на эту подробность.
- *,) Круглые скобки определяют подвыражение, которое описывает некоторое количество символов, завершаемых запятой. Мы определяем это подвыражение, потому что оно должно повторяться при поиске.
- ]*,)+ Знак + — еще один квантификатор, применяемый к предшествующему элементу (то есть к подвыражению в круглых скобках). В отличие от * знак + означает «одно или более повторений». Список, разделенный запятыми, состоит из одного или нескольких повторений подвыражения.
- ( В шаблон добавляется еще одно подвыражение: (*). Оно почти совпадает с первым, но не содержит запятой. Последний элемент списка не завершается запятой.
- Мы добавляем квантификатор {1}, чтобы разрешить вхождение ровно одного элемента списка без завершающей запятой.
- ^ Наконец, метасимволы ^ и привязывают потенциальное совпадение к началу и концу целевой строки. Это означает, что совпадением шаблона может быть только вся строка вместо некоторого подмножества ее символов.
Функция анализирует список имен и проверяет, соответствует ли он шаблону. Эта функция оптимизирована для простого обнаружения совпадения шаблона в строке, но другие функции способны на большее!
Строковые методы, поиск и замена
Следующие методы работают с регулярными выражениями из строк.
Все методы, кроме replace, можно вызывать как с объектами типа regexp в аргументах, так и со строками, которые автоматом преобразуются в объекты RegExp.
Так что вызовы эквивалентны:
var i = str.search(/\s/)
var i = str.search("\\s")
При использовании кавычек нужно дублировать \ и нет возможности указать флаги. Если регулярное выражение уже задано строкой, то бывает удобна и полная форма
var regText = "\\s" var i = str.search(new RegExp(regText, "g"))
Возвращает индекс регулярного выражения в строке, или -1.
Если Вы хотите знать, подходит ли строка под регулярное выражение, используйте метод (аналогично RegExp-методы ). Чтобы получить больше информации, используйте более медленный метод (аналогичный методу ).
Этот пример выводит сообщение, в зависимости от того, подходит ли строка под регулярное выражение.
function testinput(re, str){
if (str.search(re) != -1)
midstring = " contains ";
else
midstring = " does not contain ";
document.write (str + midstring + re.source);
}
Если в regexp нет флага , то возвращает тот же результат, что .
Если в regexp есть флаг , то возвращает массив со всеми совпадениями.
Чтобы просто узнать, подходит ли строка под регулярное выражение , используйте .
Если Вы хотите получить первый результат — попробуйте r.
В следующем примере используется, чтобы найти «Chapter», за которой следует 1 или более цифр, а затем цифры, разделенные точкой. В регулярном выражении есть флаг , так что регистр будет игнорироваться.
str = "For more information, see Chapter 3.4.5.1"; re = /chapter (\d+(\.\d)*)/i; found = str.match(re); alert(found);
Скрипт выдаст массив из совпадений:
- Chapter 3.4.5.1 — полностью совпавшая строка
- 3.4.5.1 — первая скобка
- .1 — внутренняя скобка
Следующий пример демонстрирует использование флагов глобального и регистронезависимого поиска с . Будут найдены все буквы от А до Е и от а до е, каждая — в отдельном элементе массива.
var str = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"; var regexp = //gi; var matches = str.match(regexp); document.write(matches); // matches =
Метод replace может заменять вхождения регулярного выражения не только на строку, но и на результат выполнения функции. Его полный синтаксис — такой:
var newString = str.replace(regexp/substr, newSubStr/function)
- Объект RegExp. Его вхождения будут заменены на значение, которое вернет параметр номер 2
- Строка, которая будет заменена на .
- Строка, которая заменяет подстроку из аргумента номер 1.
- Функция, которая может быть вызвана для генерации новой подстроки (чтобы подставить ее вместо подстроки, полученной из аргумента 1).
Метод не меняет строку, на которой вызван, а просто возвращает новую, измененную строку.
Чтобы осуществить глобальную замену, включите в регулярное выражение флаг .
Если первый аргумент — строка, то она не преобразуется в регулярное выражение, так что, например,
var ab = "a b".replace("\\s","..") // = "a b"
Вызов replace оставил строку без изменения, т.к искал не регулярное выражение , а строку «\s».
В строке замены могут быть такие спецсимволы:
| Pattern | Inserts |
| Вставляет «$». | |
| Вставляет найденную подстроку. | |
| Вставляет часть строки, которая предшествует найденному вхождению. | |
| Вставляет часть строки, которая идет после найденного вхождения. | |
| or | Где или — десятичные цифры, вставляет подстроку вхождения, запомненную -й вложенной скобкой, если первый аргумент — объект RegExp. |
Если Вы указываете вторым параметром функцию, то она выполняется при каждом совпадении.
В функции можно динамически генерировать и возвращать строку подстановки.
Первый параметр функции — найденная подстрока. Если первым аргументом является объект , то следующие параметров содержат совпадения из вложенных скобок. Последние два параметра — позиция в строке, на которой произошло совпадение и сама строка.
Например, следующий вызов возвратит XXzzzz — XX , zzzz.
function replacer(str, p1, p2, offset, s)
{
return str + " - " + p1 + " , " + p2;
}
var newString = "XXzzzz".replace(/(X*)(z*)/, replacer)
Как видите, тут две скобки в регулярном выражении, и потому в функции два параметра , .
Если бы были три скобки, то в функцию пришлось бы добавить параметр .
Следующая функция заменяет слова типа на :
function styleHyphenFormat(propertyName)
{
function upperToHyphenLower(match)
{
return '-' + match.toLowerCase();
}
return propertyName.replace(//, upperToHyphenLower);
}
str.replace(str|regexp, str|func)
Это универсальный метод поиска-и-замены, один из самых полезных. Этакий швейцарский армейский нож для поиска и замены в строке.
Мы можем использовать его и без регулярных выражений, для поиска-и-замены подстроки:
Хотя есть подводный камень.
Когда первый аргумент является строкой, он заменяет только первое совпадение.
Вы можете видеть это в приведённом выше примере: только первый заменяется на .
Чтобы найти все дефисы, нам нужно использовать не строку , а регулярное выражение с обязательным флагом :
Второй аргумент – строка замены. Мы можем использовать специальные символы в нем:
| Спецсимволы | Действие в строке замены |
|---|---|
| вставляет | |
| вставляет всё найденное совпадение | |
| вставляет часть строки до совпадения | |
| вставляет часть строки после совпадения | |
| если это 1-2 значное число, то вставляет содержимое n-й скобки | |
| вставляет содержимое скобки с указанным именем |
Например:
Для ситуаций, которые требуют «умных» замен, вторым аргументом может быть функция.
Она будет вызываться для каждого совпадения, и её результат будет вставлен в качестве замены.
Функция вызывается с аргументами :
- – найденное совпадение,
- – содержимое скобок (см. главу Скобочные группы).
- – позиция, на которой найдено совпадение,
- – исходная строка,
- – объект с содержимым именованных скобок (см. главу Скобочные группы).
Если скобок в регулярном выражении нет, то будет только 3 аргумента: .
Например, переведём выбранные совпадения в верхний регистр:
Заменим каждое совпадение на его позицию в строке:
В примере ниже две скобки, поэтому функция замены вызывается с 5-ю аргументами: первый – всё совпадение, затем два аргумента содержимое скобок, затем (в примере не используются) индекс совпадения и исходная строка:
Если в регулярном выражении много скобочных групп, то бывает удобно использовать остаточные аргументы для обращения к ним:
Или, если мы используем именованные группы, то объект с ними всегда идёт последним, так что можно получить его так:
Использование функции даёт нам максимальные возможности по замене, потому что функция получает всю информацию о совпадении, имеет доступ к внешним переменным и может делать всё что угодно.
Примеры шаблонов
Начнем с пары простых примеров. Первое выражение на картинке ниже ищет
последовательность из 3 букв, где первая буква это «к», вторая — любая русская буква и
третья — это «т» без учета регистра (например, «кот» или «КОТ» подходит
под этот шаблон). Второе выражение ищет в тексте время в формате .

Любое выражение начинается с символа-ограничителя (delimiter по англ.). В качестве
него обычно используют символ , но можно использовать и другие
символы, не имеющие специального назначения в регулярках, например, ,
или . Альтернативные разделители используют, если в
выражении может встречаться символ . Затем идет сам шаблон строки,
которую мы ищем, за
ним второй ограничитель и в конце может идти одна или несколько букв-флагов. Они
задают дополнительные опции при поиске текста. Вот примеры флагов:
-
— говорит, что поиск должен вестись без учета
регистра букв (по умолчанию регистр учитывается) -
— говорит, что выражение и текст, по которому идет поиск,
исплоьзуют кодировку utf-8, а не только латинские буквы. Без него поиск
русских (и любых других нелатинских) символов может работать некорректно,
потому стоит ставить его всегда.
Сам шаблон состоит из обычных символов и специальных конструкций. Ну
например, буква «к» в регулярках обозначает саму себя, а вот символы
значат «в этом месте может быть любая цифра от 0 до 5». Вот полный список
специальных символов (в мануале php их называют метасимволы),
а все остальные символы в регулярке — обычные:
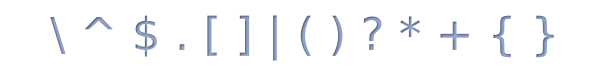
Ниже мы разберем значение каждого из этих символов (а также объясним почему буква
«ё» вынесена отдельно в первом выражении), а пока попробуем
применить наши регулярки к тексту и посмотреть, что выйдет. В php есть
специальная функция ,
которая принимает на вход регулярку, текст и пустой массив. Она проверяет,
есть ли в тексте подстрока, соответствующая данному шаблону и возвращает
, если нет,
или , если она есть. А в переданный массив в элемент с индексом
0 кладется первое найденное совпадение с регуляркой. Напишем простую
программу, применяющую регулярные выражения к разным строкам:
| Код | Результат |
|---|---|
Строка: рыжий кот + Найдено слово 'кот' Строка: рыжий крот - Ничего не найдено Строка: кит и кот + Найдено слово 'кит' |
Познакомившись с примером, изучим регулярные выражения более подробно.


Количество {n}
Самый простой квантификатор — это число в фигурных скобках: .
Он добавляется к символу (или символьному классу, или набору и т.д.) и указывает, сколько их нам нужно.
Можно по-разному указать количество, например:
- Точное количество:
-
Шаблон обозначает ровно 5 цифр, он эквивалентен .
Следующий пример находит пятизначное число:
Мы можем добавить , чтобы исключить числа длиннее: .
- Диапазон: , от 3 до 5
-
Для того, чтобы найти числа от 3 до 5 цифр, мы можем указать границы в фигурных скобках:
Верхнюю границу можно не указывать.
Тогда шаблон найдёт последовательность чисел длиной и более цифр:
Давайте вернёмся к строке .
Число – это последовательность из одной или более цифр. Поэтому шаблон будет :
Жадность¶
Регулярные выражения называются жадными по умолчанию.
Что это значит?
Возьмём например это регулярное выражение:
Предполагается, что нам нужно извлечь из строки сумму в долларах:
но что если у нас есть больше слов после числа, это отвлекает
Почему? Потому что регулярное выражение после знака совпадает с любым символом и не останавливается пока не достигнет конца строки. Затем он останавливается, потому что делает конечное пространство необязательным.
Чтобы исправить это, нам нужно указать что регулярное выражение должно быть ленивым и найти наименьшее количество совпадений. Мы можем сделать это с помощью символа после квантификатора:
Итак, символ может означать разные вещи в зависимости от своего положения, поэтому он может быть и квантификатором и индикатором ленивого режима.
Группировка в регулярных выражениях
(ABC) – Объединение несколько символов вместе. Подстрока, соответствующую этому выражению сохраняется для последующего использования.
(?:ABC) – Это выражение также производит поиск группы символов, но не сохраняет результат.
\d+(?=ABC) – выражение соответствует символам предшествующим (?=ABC), только если за ним следует “ABC”. Часть “ABC” не будет учитываться при поиске. Часть выражения “\d” приведена всего лишь для примера. На ее месте может быть любое регулярное выражение.
\d+(?!ABC) – выражение соответствует символам предшествующим (?!ABC), только если за ним НЕ следует “ABC”. Часть “ABC” не будет учитываться при поиске. Часть выражения “\d” приведена всего лишь для примера. На ее месте может быть любое регулярное выражение.
Заключение
В предыдущих статьях, были рассмотрены основы регулярных выражений, а также некоторые более сложные выражения, которые могут оказаться полезными. В следующих двух статьях объясняется, как разные символы или последовательности символов работают в регулярных выражениях.
Если после прочтения приведённых выше статей вы все еще путаетесь в регулярных выражениях, советуем вам продолжить практиковаться на примерах того, как другие люди придумывают регулярные выражения.
Оригинал статьи: https://code.tutsplus.com/tutorials/a-simple-regex-cheat-sheet—cms-31278/
Перевод: Земсков Матвей