Grep все, что можно
Содержание:
- msggrep, mboxgrep
- Любой символ
- Разница между grep, egrep, fgrep, pgrep, zgrep
- Выражения в квадратных скобках и Классы символов
- Синтаксис
- Google Docs
- Xargs
- Как используются регулярные выражения
- Linux поиск по содержимому файлов командой locate
- grep
- Other options
- Команда sed в Linux
- Приведем примеры
- Basic vs. extended regular expressions
- Заключение
msggrep, mboxgrep
Это совсем уже узко специализированная штуковина, чтобы парсить каталоги локализации. Идет в комплекте с пакетом gettext. Программа не из разряда пользовательских, но если очень нужно, можно запустить с командной строки.
Следующий экспонат — парсер почтовых ящиков mboxgrep. Проект так и не взлетел, его разработка прекращена. По идее он должен был находить паттерны в письмах и обрабатывать вывод так как будто это отдельные файлы. Однако, для начала он эти паттерны должен уметь находить.
А он не находит.
Что странно, системные вызовы все время одни и те же, вне зависимости от поиска.
Любопытно было бы узнать, завелась ли данная программа успешно у кого-нибудь?
Ну ладно, мы увлеклись, а греп семейство еще не инвентаризировано полностью.
Любой символ
Первый метасимвол, с которого мы начнём знакомство, это символ точки, который означает «любой символ». Если мы включим его в регулярное выражение, то он будет соответствовать любому символу для этой позиции символа. Пример:
grep -h '.zip' dirlist*.txt bunzip2 bzip2 bzip2recover gunzip gzip funzip gpg-zip mzip p7zip preunzip prezip prezip-bin unzip unzipsfx
Мы искали любую строку в наших файлах, которая соответствует регулярному выражению «.zip». Нужно отметить парочку интересных моментов в полученных результатах
Обратите внимание, что программа zip не была найдена. Это от того, что включение метасимвола точка в наше регулярное выражение увеличило длину, требуемую для совпадения, до четырёх символов, а поскольку имя «zip» содержит только три, то оно не соответствует
Также если какие-либо файлы из наших списков содержали расширение файла .zip, они также считались бы подходящими, поскольку символ точки в расширении файла, также подходит под условие «любой символ».
Разница между grep, egrep, fgrep, pgrep, zgrep
Различные переключатели grep исторически были включены в различные двоичные файлы. В современных системах Linux вы найдете эти переключатели доступными в команде base grep, но часто дистрибутивы поддерживают и другие команды.
Со страницы руководства для grep:
egrep является эквивалентом grep -E
Этот переключатель будет интерпретировать шаблон как расширенное регулярное выражение . Есть множество разных вещей, которые вы можете сделать с этим, но вот пример того, как выглядит использование регулярного выражения с grep.
Давайте найдем в текстовом документе строки, которые содержат две последовательные буквы «р»:
$ egrep p\{2} fruits.txt
или
$ grep -E p\{2} fruits.txt
fgrep является эквивалентом grep -F
Этот переключатель будет интерпретировать шаблон как список фиксированных строк и попытаться сопоставить любую из них. Это полезно, когда вам нужно искать символы регулярного выражения. Это означает, что вам не нужно экранировать специальные символы, как если бы вы использовали обычный grep.
$ fgrep $ License.txt There is a $100 free for commercial use.
pgrep — это команда для поиска имени запущенного процесса в вашей системе и возврата соответствующих идентификаторов процесса. Например, вы можете использовать его, чтобы найти идентификатор процесса демона SSH:
$ pgrep sshd
По функциям это похоже на простую передачу вывода команды ‘ps’ в grep.
Вы можете использовать эту информацию, чтобы убить работающий процесс или устранить проблемы со службами, работающими в вашей системе.
zgrep используется для поиска сжатых файлов по шаблону. Это позволяет вам искать файлы внутри сжатого архива без необходимости сначала распаковывать этот архив, в основном экономя вам дополнительный шаг или два.
$ zgrep apple fruits.txt.gz
zgrep также работает с tar-файлами, но кажется, что он говорит только о том, удалось ли найти совпадение.
$ zgrep apple fruits.tar.gz
Мы упоминаем об этом, потому что файлы, сжатые с помощью gzip, обычно являются архивами tar.
Выражения в квадратных скобках и Классы символов
В дополнение к совпадению любого символа в заданной позиции в нашем регулярном выражении, мы также, используя выражения в квадратных скобках, можем задать совпадение единичного символа из указанного набора символов. С выражениями в квадратных скобках мы можем указать набор символов для соответствия (включая символы, которые в противном случае были бы истолкованы как метасимволы). В этом примере, используя набор из двух символов:
grep -h 'zip' dirlist*.txt bzip2 bzip2recover gzip
мы найдём любые строчки, содержащие строки «bzip» или «gzip».
Набор может содержать любое количество символов, а метасимволы теряют своё специальное значение, когда помещаются внутрь квадратных скобок. Тем не менее, есть два случая в которых метасимволы, используемые внутри квадратных скобок, имеют различные значения. Первый – это каретка (^), которая используется для указания отрицания; второй – это тире (-), которое используется для указания диапазона символов.
Отрицание
Если первым символом выражения в квадратных скобках является каретка (^), то остальные символы принимаются как набор символов, которые не должны присутствовать в заданной позиции символа. Сделаем это изменив наш предыдущий пример:
grep -h 'zip' dirlist*.txt bunzip2 gunzip funzip gpg-zip mzip p7zip preunzip prezip prezip-bin unzip unzipsfx
С активированным отрицанием, мы получили список файлов, которые содержат строку «zip», перед которой идёт любой символ, кроме «b» или «g»
Обратите внимание, что zip не был найден. Отрицаемый набор символов всё равно требует символ на заданной позиции, но символ не должен быть членом инвертированного набора.
Символ каретки вызывает отрицание только если он является первым символом внутри выражения в квадратных скобках; в противном случае, он теряет своё специальное назначение и становится обычным символом из набора.
Традиционные диапазоны символов
Если мы хотим сконструировать регулярное выражение, которое должно найти каждый файл из нашего списка, начинающийся на заглавную букву, мы можем сделать следующее:
grep -h '^' dirlist*.txt MAKEDEV GET HEAD POST VBoxClient X X11 Xorg ModemManager NetworkManager VBoxControl VBoxService
Суть в том, что мы разместили все 26 заглавных букв в выражение внутри квадратных скобок. Но мысль печатать их все не вызывает энтузиазма, поэтому есть другой путь:
grep -h '^' dirlist*.txt
Используя трёхсимвольный диапазон, мы можем сократить запись из 26 букв. Таким способом можно выразить любой диапазон символов, включая сразу несколько диапазонов, такие, как это выражение, которое соответствует всем именам файлов, начинающихся с букв и цифр:
grep -h '^' dirlist*.txt
В диапазонах символов мы видим, что символ чёрточки трактуется особым образом, поэтому как мы можем включить символ тире в выражение внутри квадратных скобок? Сделав его первым символом в выражении. Рассмотрим два примера:
grep -h '' dirlist*.txt
Это будет соответствовать каждому имени файла, содержащему заглавную букву. При этом:
grep -h '' dirlist*.txt
будет соответствовать каждому имени файла, содержащему тире, или заглавную «A», или заглавную «Z».
Классы символов POSIX
Подробнее о POSIX вы можете почитать в Википедии.
В POSIX имеются свои классы символов, которые вы можете использовать в регулярных выражениях:
| Класс символов | Описание |
|---|---|
| Алфавитно-цифровые символы. В ASCII эквивалентно: | |
| То же самое, что и , с дополнительным символом подчёркивания (_). | |
| Алфавитные символы. В ASCII эквивалентно: | |
| Включает символы пробела и табуляции. | |
| Управляющие коды ASCII. Включает ASCII символы с 0 до 31 и 127. | |
| Цифры от нуля до девяти. | |
| Видимые символы. В ASCII сюда включены символы с 33 по 126. | |
| Буквы в нижнем регистре. | |
| Символы пунктуации. В ASCII эквивалентно: [-!»#$%&'()*+,./:;?@_`{|}~] | |
| Печатные символы. Все символы в плюс символ пробела. | |
| Символы белых пробелов, включающих пробел, табуляцию, возврат каретки, новую строку, вертикальную табуляцию и разрыв страницы. В ASCII эквивалентно: | |
| Символы в верхнем регистре. | |
| Символы, используемые для выражения шестнадцатеричных чисел. В ASCII эквивалетно: |
В этих выражениях квадратные скобки и двоеточия являются частью записи класса символов (диапазонов).
Внимание: в зависимости от настроек локали, , , и другие буквенные диапазоны могут включать буквы вашего алфавита, например, русского. Т.е
может соответствовать не , а .
Синтаксис
Рассмотрим синтаксис.
grep шаблон
Или так:
Команда | grep шаблон
Здесь под параметрами понимаются аргументы, с помощью которых настраивается поиск и вывод на экран. Например нужно найти слово «линукс», и не учитывать регистр при поиске. Тогда нужно использовать опцию «-i».
Шаблон — это выражение или строка.
Имя файла — где искать.
Основные параметры:
—help. Вывести справочную информацию.
-i. Не учитывать регистр при поиске.
-V. Узнать текущую версию.
-v. Инвертированный поиск.
-s. Не выводить на экран сообщения об ошибкам. Например сообщение о несуществующих файлах.
-r. Поиск в каталогах, подкаталогах или рекурсивный grep.
-w. Искать как слово с пробелами.
-с. Опция считает количество вхождений (счетчик).
-e. Регулярные выражения.
Примеры
Найдем все файлы в текущей директории где встречается слово «linux».
grep linux ./*
Здесь:
- linux — слово которое нужно искать;
- точка — текущая директория;
- звездочка — искать во всех файлах.
Чтобы начать поиск без учета регистра необходимо добавить аргумент «-i». В нашем примере получится так:
grep -i linux ./*
Поиск в конкретном документе. Для примера найдем в документе «test» слово «хороший». Для этого с помощью утилиты «cd» зайдем в текущую директорию, где лежит файл «test». В моем случаи он находится в домашнем каталоге, я ввожу просто «cd».
grep хороший test
Здесь:
- хороший — слово которое нужно найти;
- test — файл, где искать.
Рекурсивный поиск. Чтобы найти определенный текст в определенной директории, используют рекурсивный поиск. Для этого необходимо использовать параметр «-r». Найдем слово «vseprolinux» в домашнем каталоге root и его подкаталогах.
grep -r vseprolinux /etc/root
Найдем три слова сразу в одной строке «все про Линукс». Для этого будем использовать вертикальную черту и введет «grep» три раза.
grep «все» test | grep «про» | grep «Линукс»
Команда grep может сообщить сколько раз встречается слово. Нам поможет опция -с. Посчитаем сколько раз встречается слово «site» в документе «file».
grep -c site file
Как видно на скриншоте выше, в файле «file» три раза встречается слово «site». Однако команда также считает выражение «mysite» за «site». Как сделать чтобы mysite не попал под счетчик? Добавим опцию «-w.»
grep -cw site file
Регулярные выражения.
Регулярные выражение в утилите «grep» — это мощная функция, которая расширяет возможности поиска. Чтобы активировать эту функцию или режим, используется аргумент «-e».
Символы в выражениях:
- $ — конец строки;
- ^ — начало строки;
- [] — указывается диапазон значений или конкретные через запятую.
Найдем цифры 1-5 в документе «file».
grep file
В скобках написано диапазон значений от одного до пяти, также можно написать конкретные значения через запятую, так:
Google Docs
Google Docs – это знакомая многим система создания и редактирования текстовых файлов, презентаций и таблиц. За последний год в этом сервисе появилось несколько новых интересных функций, которые очень упростили работу с документами.
Теперь пользователи могут не печатать текст, а просто проговаривать его в микрофон. Благодаря максимально точной системе распознавания слов от Google, итоговый результат будет содержать меньше 5% ошибок. Конечно же, этот показатель также зависит и от качества микрофона или от особенностей произношения фраз.
Рис.8 – пример работы в Google Docs
Теперь и сам файл можно редактировать с помощью голосовых указаний. Просто озвучьте название функции, чтобы программа выделила нужную часть текста или вырезала её. Пока настроена поддержка более чем 300 команд. Разработчики прислушались к желаниям юзеров и добавили поддержку документов из Open Office.
Преимущества:
- Быстрая отправка файлов по Gmail;
- Файлы других форматов автоматически преобразовываются в расширение для Google Docs;
- Упрощенный интерфейс. Главное окно больше не загружено большим количеством опций. Большинство из них спрятано в отдельных вкладках.
Недостатки:
- Документы хранятся не на отдельном сервере, а на облаке, которое указал сам пользователь. Потеряете доступ к хранилищу – не сможете восстановить документы;
- Часто из-за обновления сайта могут возникать зависания.
Xargs
Это удивительная команда работает по прицепу, берет данные из стандартного ввода или из файла, разбивает их в соответствии с указанными параметрами, а затем передает другой программе в качестве аргумента. Xargs выполняется до тех пор пока данные из потока не исчерпаны. Теперь давайте рассмотрим несколько простых примеров.
Разбивай стандартный поток на аргументы.
–n — Указываем количество возвращаемых аргументов.
echo 1 2 3 4 | xargs -n 1
Теперь зададим разделитель аргументов.
–d — Указывает на разделитель для вывода аргументов.
echo '1-2-3-4' | xargs -d '-' -n 1
Вот более интересный пример где xargs используется для передачи файлов которых надо удалить.
find . -name "*.txt"| xargs rm -rf
Вся суть использования xargs это дробления входящих аргументов для последующей передачи аргументов другим программам.
Как используются регулярные выражения
Текстовые данные играют важную роль во всех Unix-подобных системах, таких как Linux. Среди прочего, текстом является и вывод консольных программ, и файлы конфигурации, отчётов и т.д. Регулярные выражения являются (пожалуй) одной из самых сложных концепций по работе с текстом, поскольку предполагают высокий уровень абстракции. Но время, потраченное на их изучение, с лихвой окупится. Умея использовать регулярные выражения, вы сможете делать удивительные вещи, хотя их полная ценность может быть не сразу очевидной.
В этой статье будет рассмотрено использование регулярных выражений вместе с командой grep. Но их применение не ограничивается только этим: регулярные выражения поддерживаются другими командами Linux, многими языками программирования, применяются при конфигурации (например, в настройках правил mod_rewrite в Apache), а также некоторые программы с графическим интерфейсом позволяют устанавливать правила для поиска/копирования/удаления с поддержкой регулярных выражений. Даже в популярной офисной программе Microsoft Word для поиска и замены текста вы можете использовать регулярные выражения и подстановочные символы.
Linux поиск по содержимому файлов командой locate
Поиск, производимый командой locate весьма быстр. Однако учитывайте тот факт, что системная база данных может быть не живой на момент осуществления операции. Механизм сканирования файловой системы, время его проведения и вобщем наличие такого инструмента может разниться в различных дистрибутивах Linux. Команда locate может быть полезна лишь при поиске файла по его имени. Однако для проверки текстового содержимого документов на вступление искомых данных нужно использовать другой инструмент.
Данная команда, как правило, работает быстрее и может с легкостью производить поиск (в широком смысле — стремление добиться чего-либо, найти что-либо; действия субъекта, направленные на получение нового или утерянного (забытого): новой информации (поиск информации), данных,) по всей файловой системы. Linux имеет специальную команду grep, какая принимает шаблон для поиска и имя файла (именованная область данных на носителе информации). В случае нахождения совпадений, они будут выведены в терминал. В всеобщем виде выражение можно составить как «grep шаблон_поиска имя_файла». Чтобы отыскать файлы с помощью команды locate, просто используйте следующий синтаксис:
К образцу, чтобы возвращать только файлы, содержащие сам запрос, вместо того чтобы вводить каждый файл, который содержит запрос в ведущих к нему каталогах, можно утилизировать флаг –b (чтоб искать только basename, базовое имя файла):
Команды find и locate – отличные инструменты для поиска файлов в UNIX‐подобных операционных системах. Любая из этих утилит имеет свои преимущества. Мы рассмотрели использование команд для поиска и фильтрации вывода бригад в операционной системе Linux. При правильном применении эта утилита станет мощным инструментом в ваших руках. Несмотря на то, что команды find и locate сами по себе очень мощны, их действие возможно расширить, комбинируя их с другими командами. Научившись работать с find и locate, попробуйте чистить их результаты при помощи команд wc, sort и grep.
grep
Основной программой, которую мы будем использовать для регулярных выражений, является наш старый приятель, . Имя «grep» на самом деле происходит от фразы «global regular expression print», поэтому мы можем видеть, что grep имеет какое-то отношение к регулярным выражениям. По сути, grep ищет в текстовых файлах текст, который подходит под указанное регулярное выражение и выводит в стандартный вывод любую строку, содержащую соответствие.
grep может делать поиск по тексту, получаемому в стандартном вводе, например:
ls /usr/bin | grep zip
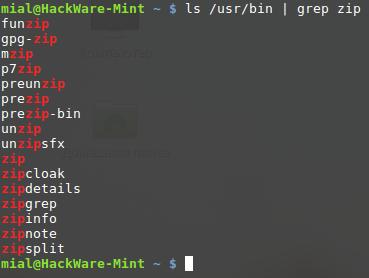
Эта команда выведет список файлов в директории /usr/bin, чьи имена содержат подстроку «zip».
Программа grep может искать по тексту в файлах.
Общий синтаксис использования:
grep regex
Где:
- regex – это регулярное выражение.
- – один или несколько файлов, в которых будет проводиться поиск по регулярному выражению.
и могут отсутствовать.
Список самых часто используемых опций grep:
| Опция | Описание |
|---|---|
| -i | Игнорировать регистр. Не делать различия между большими и маленькими символами. Также можно задать опцией —ignore-case. |
| -v | Инвертировать соответствие. Обычно grep печатает строки, которые содержат соответствие. Эта опция приводит к тому, что grep выводит каждую строку, которая не содержит соответствия. Также можно использовать —invert-match. |
| -c | Печатать количество соответствий (или несоответствий, если указана опция -v) вместо самих строк. Можно также указывать опцией —count. |
| -l | Вместо самих строк печатать имя каждого файла, который содержит соответствие. Можно указать опцией —files-with-matches. |
| -L | Как опция -l, но печатает только имена файлов, которые не содержат совпадений. Другое имя опции —files-withoutmatch. |
| -n | Добавление к началу каждой совпавшей строке номера строчки внутри файла. Другое имя опции —line-number. |
| -h | Для поиска по нескольким файлам, подавлять вывод имени файла. Также можно указать опцией —no-filename. |
Чтобы полнее исследовать grep, давайте создадим несколько текстовых файлов для поиска:
ls /bin > dirlist-bin.txt ls /usr/bin > dirlist-usr-bin.txt ls /sbin > dirlist-sbin.txt ls /usr/sbin > dirlist-usr-sbin.txt ls dirlist*.txt dirlist-bin.txt dirlist-sbin.txt dirlist-usr-bin.txt dirlist-usr-sbin.txt
Мы можем выполнить простой поиск по нашему списку файлов следующим образом:
grep bzip dirlist*.txt dirlist-bin.txt:bzip2 dirlist-bin.txt:bzip2recover

В этом примере grep ищет по всем перечисленным файлам строку bzip и находит два соответствия, оба в файле dirlist-bin.txt. Если нас интересует только список файлов, содержащих соответствия, а не сами подходящие строки, мы можем указать опцию -l:
grep -l bzip dirlist*.txt dirlist-bin.txt
И наоборот, если бы мы хотели увидеть только список файлов, которые не содержали совпадений, мы могли бы сделать это:
grep -L bzip dirlist*.txt dirlist-sbin.txt dirlist-usr-bin.txt dirlist-usr-sbin.txt
Если вывод отсутствует – значит файлы, удовлетворяющие условиям не найдены.
Other options
| —line-buffered | Use line buffering on output. This can cause a performance penalty. |
| —mmap | If possible, use the mmap system call to read input, instead of the default read system call. In some situations, —mmap yields better performance. However, —mmap can cause undefined behavior (including core dumps) if an input file shrinks while grep is operating, or if an I/O error occurs. |
| -U, —binary | Treat the file(s) as binary. By default, under MS-DOS and MS-Windows, grep guesses the file type by looking at the contents of the first 32 KB read from the file. If grep decides the file is a text file, it strips the CR characters from the original file contents (to make regular expressions with ^ and $ work correctly). Specifying -U overrules this guesswork, causing all files to be read and passed to the matching mechanism verbatim; if the file is a text file with CR/LF pairs at the end of each line, this causes some regular expressions to fail. This option has no effect on platforms other than MS-DOS and MS-Windows. |
| -z, —null-data | Treat the input as a set of lines, each terminated by a zero byte (the ASCII NUL character) instead of a newline. Like the -Z or —null option, this option can be used with commands like sort -z to process arbitrary file names. |
Команда sed в Linux
Сначала рассмотрим синтаксис команды:
$ sed опции -e команды файл
А вот её основные опции:
- -n, —quiet — не выводить содержимое буфера шаблона в конце каждой итерации;
- -e — команды, которые надо выполнить для редактирования;
- -f — прочитать команды редактирования из файла;
- -i — сделать резервную копию файла перед редактированием;
- -l — указать свою длину строки;
- -r — включить поддержку расширенного синтаксиса регулярных выражений;
- -s — если передано несколько файлов, рассматривать их как отдельные потоки, а не как один длинный.
Я понимаю, что сейчас всё очень сложно, но к концу статьи всё прояснится.
1. Как работает sed
Теперь нужно понять как работает команда sed. У утилиты есть два буфера, это активный буфер шаблона и дополнительный буфер. Оба изначально пусты. Программа выполняет заданные условия для каждой строки в переданном ей файле.
sed читает одну строку, удаляет из неё все завершающие символы и символы новой строки и помещает её в буфер шаблона. Затем выполняются переданные в параметрах команды, с каждой командой может быть связан адрес, это своего рода условие и команда выполняется только если подходит условие.
Когда всё команды будут выполнены и не указана опция -n, содержимое буфера шаблона выводится в стандартный поток вывода перед этим добавляется обратно символ перевода строки. если он был удален. Затем запускается новая итерация цикла для следующей строки.
Если не используются специальные команды, например, D, то после завершения одной итерации цикла содержимое буфера шаблона удаляется. Однако содержимое предыдущей строки хранится в дополнительном буфере и его можно использовать.
2. Адреса sed
Каждой команде можно передать адрес, который будет указывать на строки, для которых она будет выполнена:
- номер — позволяет указать номер строки, в которой надо выполнять команду;
- первая~шаг — команда будет выполняется для указанной в первой части сроки, а затем для всех с указанным шагом;
- $ — последняя строка в файле;
- /регулярное_выражение/ — любая строка, которая подходит по регулярному выражению. Модификатор l указывает, что регулярное выражение должно быть не чувствительным к регистру;
- номер, номер — начиная от строки из первой части и заканчивая строкой из второй части;
- номер, /регулярное_выражение/ — начиная от сроки из первой части и до сроки, которая будет соответствовать регулярному выражению;
- номер, +количество — начиная от номера строки указанного в первой части и еще плюс количество строк после него;
- номер, ~число — начиная от строки номер и до строки номер которой будет кратный числу.
Если для команды не был задан адрес, то она будет выполнена для всех строк. Если передан один адрес, команда будет выполнена только для строки по этому адресу. Также можно передать диапазон адресов. Тогда адреса разделяются запятой и команда будет выполнена для всех адресов диапазона.
3. Синтаксис регулярных выражений
Вы можете использовать такие же регулярные выражения, как и для Bash и популярных языков программирования. Вот основные операторы, которые поддерживают регулярные выражения sed Linux:
- * — любой символ, любое количество;
- \+ — как звездочка, только один символ или больше;
- \? — нет или один символ;
- \{i\} — любой символ в количестве i;
- \{i,j\} — любой символ в количестве от i до j;
- \{i,\} — любой символ в количестве от i и больше.
4. Команды sed
Если вы хотите пользоваться sed, вам нужно знать команды редактирования. Рассмотрим самые часто применяемые из них:
- # — комментарий, не выполняется;
- q — завершает работу сценария;
- d — удаляет буфер шаблона и запускает следующую итерацию цикла;
- p — вывести содержимое буфера шаблона;
- n — вывести содержимое буфера шаблона и прочитать в него следующую строку;
- s/что_заменять/на_что_заменять/опции — замена символов, поддерживаются регулярные выражения;
- y/символы/символы — позволяет заменить символы из первой части на соответствующие символы из второй части;
- w — записать содержимое буфера шаблона в файл;
- N — добавить перевод строки к буферу шаблона;
- D — если буфер шаблона не содержит новую строку, удалить его содержимое и начать новую итерацию цикла, иначе удалить содержимое буфера до символа перевода строки и начать новую итерацию цикла с тем, что останется;
- g — заменить содержимое буфера шаблона, содержимым дополнительного буфера;
- G — добавить новую строку к содержимому буфера шаблона, затем добавить туда же содержимое дополнительного буфера.
Утилите можно передать несколько команд, для этого их надо разделить точкой с запятой или использовать две опции -e. Теперь вы знаете всё необходимое и можно переходить к примерам.
Приведем примеры
. (точка)
Используется для соответствия любому символу, который встречается в поисковом запросе. Например, можем использовать точку как:
Это регулярное выражение означает, что мы ищем слово, которое начинается с ‘d’, оканчивается на ‘g’ и может содержать один любой символ в середине файла с именем ‘file1’. Точно так же мы можем использовать символ точки любое количество раз для нашего шаблона поиска, например:
Этот поисковый термин будет искать слово, которое начинается с ‘T’, оканчивается на ‘h’ и может содержать любые шесть символов в середине.
Квадратные скобки используются для определения диапазона символов. Например, когда нужно искать один из перечисленных символов, а не любой символ, как в случае с точкой:
Здесь мы ищем слово, которое начинается с ‘N’, оканчивается на ‘n’ и может иметь только ‘o’, ‘e’ или ‘n’ в середине. В квадратных скобках можно использовать любое количество символов. Мы также можем определить диапазоны, такие как ‘a-e’ или ‘1-18’, как список совпадающих символов в квадратных скобках.
Это похоже на оператор отрицания для регулярных выражений. Использование означает, что поиск будет включать в себя все символы, кроме тех, которые указаны в квадратных скобках. Например:
Это означает, что у нас могут быть все слова, которые начинаются с ‘St’, оканчиваются буквой ‘d’ и не содержат цифр от 1 до 9.
До сих пор мы использовали примеры регулярных выражений, которые ищут только один символ. Но что делать в иных случаях? Допустим, если требуется найти все слова, которые начинаются или оканчиваются символом или могут содержать любое количество символов в середине. С этой задачей справляются так называемые метасимволы-квантификаторы, определяющие сколько раз может встречаться предшествующее выражение: + * & ?
{n}, {n m}, {n, } или { ,m} также являются примерами других квантификаторов, которые мы можем использовать в терминах регулярных выражений.
* (звездочка)
На следующем примере показано любое количество вхождений буквы ‘k’, включая их отсутствие:
Это означает, что у нас может быть совпадение с ‘lake’ или ‘la’ или ‘lakkkkk’.
+
Следующий шаблон требует, чтобы хотя бы одно вхождение буквы ‘k’ в строке совпадало:
Здесь буква ‘k’ должна появляться хотя бы один раз, поэтому наши результаты могут быть ‘lake’ или ‘lakkkkk’, но не ‘la’.
?
В следующем шаблоне результатом будет строка bb или bab:
С заданным квантификатором ‘?’ мы можем иметь одно вхождение символа или ни одного.
Важное примечание! Предположим, у нас есть регулярное выражение:
И мы получаем результаты ‘Small’, ‘Silly’, и ещё ‘Susan is a little to play ball’. Но почему мы получили ‘Susan is a little to play ball’, ведь мы искали только слова, а не полное предложение?
Все дело в том, что это предложение удовлетворяет нашим критериям поиска: оно начинается с буквы ‘S’, имеет любое количество символов в середине и заканчивается буквой ‘l’. Итак, что мы можем сделать, чтобы исправить наше регулярное выражение, чтобы в качестве выходных данных мы получали только слова вместо целых предложений.
Для этого в регулярное выражение нужно добавить квантификатор ‘?’:
или символ экранирования
Символ » используется, когда необходимо включить символ, который является метасимволом или имеет специальное значение для регулярного выражения. Например, требуется найти все слова, заканчивающиеся точкой. Для этого можем использовать выражение:
Оно будет искать и сопоставлять все слова, которые заканчиваются точкой.
Итак, вы получили общее представление о том, как работают регулярные выражения. Практикуйтесь как можно больше, создавайте регулярные выражения и старайтесь включать их в свою работу как можно чаще. Проверять правильность использования своих регулярных выражений на конкретном примере можно на специальном сайте.
Basic vs. extended regular expressions
In basic regular expressions the metacharacters ?, +, {, |, (, and ) lose their special meaning; instead use the backslashed versions \?, \+, \{, \|, \(, and \).
Traditional versions of egrep did not support the { metacharacter, and some egrep implementations support \{ instead, so portable scripts should avoid { in grep -E patterns and should use to match a literal {.
GNU grep -E attempts to support traditional usage by assuming that { is not special if it would be the start of an invalid interval specification. For example, the command grep -E ‘{1’ searches for the two-character string {1 instead of reporting a syntax error in the regular expression. POSIX allows this behavior as an extension, but portable scripts should avoid it.
Заключение
Если вы успешно освоили материал из этой статьи, то вас также может заинтересовать статья «Команда grep: опции, регулярные выражения и примеры использования», в которой более подробно рассматриваются все опции команды grep, там вы сможете найти что-то новое о регулярных выражениях (например, об обратных отсылках), а также познакомитесь с несколькими дополнительными примерами регулярных выражений.
Также смотрите практические примеры поиска и применения опций в статьях:
- Как найти все файлы, содержащие определённый текст
- Как использовать кавычки в регулярных выражениях grep
- Как обработать каждую строку, полученную от команды grep