Генерация http запросов
Содержание:
- Форматы сообщений запроса/ответа
- HyperText Transfer Protocol
- Структура протокола
- История
- Какими бывают протоколы Интернета
- Несколько HTTP соединений
- Разработка протокола HTTP
- Особенности HTTP
- Что такое HTTP/2 и зачем он нужен
- Статусы HTTP
- Стандарты (протокола) обмена информацией
- Загрузка нескольких ресурсов
- Как работает запрос Conditional GET
- 3.12 Еденицы измерения диапазонов (Range Units).
- Коды состояния
- 3.2 Универсальные Идентификаторы Ресурсов (URI).
- Инструменты для просмотра сетевого трафика по HTTP (* поток данных в передающей среде; состоит из передаваемых данных и служебной информации, необходимой для организации их прохождения)
- Symbols
- Формат ответа
- Библиотеки для работы с HTTP — jQuery AJAX
Форматы сообщений запроса/ответа
На следующем изображении вы можете увидеть схематично оформленный процесс отправки запроса клиентом, обработка и отправка ответа сервером.

Давайте посмотрим на структуру передаваемого сообщения через HTTP:
message = <start-line>
*(<message-header>)
CRLF
<start-line> = Request-Line | Status-Line
<message-header> = Field-Name ':' Field-Value
Между заголовком и телом сообщения должна обязательно присутствовать пустая строка. Заголовков может быть несколько:
Тело ответа может содержать полную информацию или её часть, если активирована соответствующая возможность (Transfer-Encoding: chunked). HTTP/1.1 также поддерживает заголовок Transfer-Encoding.
Общие заголовки
Вот несколько видов заголовков, которые используются как в запросах, так и в ответах:
general-header = Cache-Control
| Connection
| Date
| Pragma
| Trailer
| Transfer-Encoding
| Upgrade
| Via
| Warning
Что-то мы уже рассмотрели в этой статье, что-то подробней затронем во второй части.
Заголовок via используется в запросе типа TRACE, и обновляется всеми прокси-серверами.
Заголовок Pragma используется для перечисления собственных заголовков. К примеру, Pragma: no-cache — это то же самое, что Cache-Control: no-cache. Подробнее об этом поговорим во второй части.
Заголовок Date используется для хранения даты и времени запроса/ответа.
Заголовок Upgrade используется для изменения протокола.
Transfer-Encoding предназначается для разделения ответа на несколько фрагментов с помощью Transfer-Encoding: chunked. Это нововведение версии HTTP/1.1.
Заголовки сущностей
В заголовках сущностей передаётся мета-информация контента:
entity-header = Allow
| Content-Encoding
| Content-Language
| Content-Length
| Content-Location
| Content-MD5
| Content-Range
| Content-Type
| Expires
| Last-Modified
Все заголовки с префиксом Content- предоставляют информацию о структуре, кодировке и размере тела сообщения.
Заголовок Expires содержит время и дату истечения сущности. Значение “never expires” означает время + 1 код с текущего момента. Last-Modified содержит время и дату последнего изменения сущности.
С помощью данных заголовков, можно задать нужную для ваших задач информацию.
HyperText Transfer Protocol
Интернет протокол HTTP – HyperText Transfer Protocol является протоколом передачи гипертекста. Он предназначен для передачи различной информации между клиентом и сервером и является символьно-ориентированным клиент-серверным протоколом.
В основе протокола лежит технология «клиент-сервер». Это предполагает наличие потребителей – клиентов. Клиенты инициализируют соединение и посылают запрос и наличие поставщиков – серверов. Сервер ждет соединения чтобы получить запрос, производит нужные операции и возвращает клиенту сообщение с результатом.
Всего было четыре версии протокола. Самый первый вариант интернет протокола HTTP 0.9 был выпущен в 1991 году и впервые издан в январе 1992 года. Он привел к урегулированию норм и правил взаимосвязи между клиентами и серверами HTTP, а соответственно к точному разграничению функций между этими элементами. Были запротоколированы основные синтаксические и семантические принципы и положения.
В феврале 2015 года вышли последние редакции черновика очередной версии протокола. Протокол HTTP 2 отличает от предшествующих протоколов то, что он является бинарным. Его основные ключевые особенности: мультиплексирование запросов, последовательность приоритетов для запросов, уплотнение заголовков. Можно загружать несколько элементов параллельно, при помощи одного TCP-соединения, поддержка push-уведомлений серверной стороны.
Структура протокола
Запрос
Сообщение-запрос от клиента к серверу включает в себя, в пределах первой строки сообщения, метод, который должен быть использован для ресурса, идентификатор ресурса и код версии используемого протокола.
Request = Request-Line
*( generalheader
| requestheader
| entityheader )
CRLF
Отклик
После получения и интерпретации сообщения-запроса, сервер реагирует, посылая HTTP сообщение отклик.
Response = Status-Line ; Раздел 5.1 *( general-header ; Раздел 3.5 | response-header ; Раздел 5.2 | entity-header ) ; Раздел 6.1 CRLF ; Раздел 6.2
Отправив HTTP-запрос серверу, клиент ожидает ответа. HTTP-ответ выглядит в целом аналогично запросу: статусная строка, список заголовков и тело ответа.
HTTP/1.1 200 OK Server: nginx/0.5.35 Date: Tue, 22 Apr 2008 10:18:08 GMT Content-Type: text/plain; charset=utf-8 Connection: close Last-Modified: Fri, 30 Nov 2007 12:46:53 GMT ETag: ``27e74f-43-4750063d'' Accept-Ranges: bytes Content-Length: 34 User-agent: * Disallow: /people
Объект и соединение
Сообщения запрос и отклик могут нести в себе объект, если это не запрещено методом запроса или статусным кодом отклика. Объект состоит из полей заголовка объекта и тела объекта, хотя некоторые отклики включают в себя только заголовки объектов.
В данном разделе, как отправитель, так и получатель соотносятся к клиенту или серверу, в зависимости от того, кто отправляет и кто получает объект.
Структура ресурса и объекта
Постоянное HTTP соединение имеет много преимуществ:
- При открытии и закрытии TCP соединений можно сэкономить время CPU и память, занимаемую управляющими блоками протокола TCP.
- HTTP запросы и отклики могут при установлении связи буферизоваться (pipelining), образуя очередь. Буферизация позволяет клиенту выполнять множественные запросы, не ожидая каждый раз отклика на запрос, используя одно соединение TCP более эффективно и с меньшими потерями времени.
- Перегрузка сети уменьшается за счет сокращения числа пакетов, сопряженных с открытием и закрытием TCP соединений, предоставляя достаточно времени для детектирования состояния перегрузки.
- HTTP может функционировать более эффективно, так как сообщения об ошибках могут доставляться без потери TCP связи.Клиенты, использующие будущие версии HTTP, могут испытывать новые возможности, взаимодействуя со старым сервером, они могут после неудачи попробовать старую семантику. HTTP реализациям следует пользоваться постоянными соединениями.
Клиенты
Первоначально протокол HTTP разрабатывался для доступа к гипертекстовым документам Всемирной паутины. Поэтому основными реализациями клиентов являются браузеры (агенты пользователя). Для просмотра сохранённого содержимого сайтов на компьютере без соединения с Интернетом были придуманы офлайн-браузеры. При нестабильном соединении для загрузки больших файлов используются Менеджеры закачек. Они позволяют в любое время докачать указанные файлы после потери соединения с веб-сервером. Виртуальные атласы тоже используют HTTP.
История
- HTTP/0.9
- HTTP был предложен в марте 1991 года Бернерс-Ли,Тимом Бернерсом-Ли, работавшим тогда в CERN, как механизм для доступа к документам в Интернете и облегчения навигации посредством использования гипертекста. Самая ранняя версия протокола HTTP/0.9 была впервые опубликована в январе 1992г. (хотя реализация датируется 1990 годом). Спецификация протокола привела к упорядочению правил взаимодействия между клиентами и серверами HTTP, а также чёткому разделению функций между этими двумя компонентами. Были задокументированы основные синтаксические и семантические положения.
- HTTP/1.0
- HTTP/1.1
- Текущая версия протокола, принята в июне 1999 года. Впервые спецификация HTTP/1.1 была опубликована в январе 1997. Также разъяснено допустимое поведение клиента (браузера), сервера и прокси-серверов в некоторых сомнительных ситуациях. То есть версия 1.1 появилась всё-таки в 1997 году. Новым в этой версии был режим «постоянного соединения»: TCP-соединение может оставаться открытым после отправки ответа на запрос, что позволяет посылать несколько запросов за одно соединение. Клиент теперь обязан посылать информацию об имени хоста, к которому он обращается, что сделало возможной более простую организацию виртуального хостинга.
- HTTP/2
- 11 февраля 2015 года опубликованы финальные версии черновика следующей версии протокола. В отличие от предыдущих версий, протокол HTTP/2 является бинарным. Среди ключевых особенностей мультиплексирование запросов, расстановка приоритетов для запросов, сжатия заголовков, загрузка нескольких элементов параллельно, посредством одного TCP соединения, поддержка проактивных push-уведомлений со стороны сервера.
Какими бывают протоколы Интернета
На сегодняшний день известно несколько разновидностей протоколов Интернета. Они имеют следующие обозначения:
- HTTP;
- DNS;
- ICMP;
- FTP;
- UDP;
- TCP/IP — название протокола, являющегося основным для интернет-сетей.
Обратите внимание! Различия между этими решениями кроются в уровнях назначения
И здесь можно разделить решения по нескольким веткам:
- физические уровни. Предполагают, что соединение создаётся при помощи витой пары, оптических волокон;
- ARP-уровень с драйверами устройств;
- сетевой уровень со стандартными ICMP, IP;
- транспортный уровень — UDP и TCP;
- прикладной. Сюда входят стандартные протоколы сети Интернет типа NFS, DNS, FTP, HTTP.
ISO/OSI — система стандартизации, которая используется абсолютно для всех решений. Благодаря этому не возникает сбоев у разнообразных платформ, даже если используются разные операционные системы, оборудование поставляют разные производители. Сейчас такие детали практически не имеют значения.
Обратите внимание! Для функционирования Интернета используется протокол каждого уровня
Несколько HTTP соединений
Еще один вариант, как можно увеличить скорость загрузки web-страниц это использовать несколько HTTP соединений. Клиент открывает несколько соединений с web сервер и каждое соединение используется для загрузки разных ресурсов.
Например, первое соединение для загрузки стилевого файла, следующие соединение для загрузки javascript и другие соединения для передачи различных картинок. Каждое такое соединение может быть постоянным и использоваться для загрузки нескольких ресурсов, а также внутри таких соединений можно использовать HTTP pipelining. Почти все современные браузеры используют несколько HTTP соединений как правило от 4 до 8.
Разработка протокола HTTP
HTTP — аббревиатура, расшифровав которую получаем HyperText Transfer Prоtocоl — «протокол передачи гипертекста». Обычно гипертекст представляется набором текстов, содержащих узлы перехода между ними, которые позволяют избирать читаемые сведения или последовательность чтения.
В компьютерной терминологии, гипертекст — текст, сформированный с помощью языка разметки, потенциально содержащий в себе гиперссылки, то есть ссылки на другой элемент в самом документе, а также на другой объект, расположенный на локальном диске или в компьютерной сети, либо на элементы этого объекта.
Разработчиком протокола HTTP был британский учёный и сотрудник ЦЕРН Тим Бернерс-Ли — идеолог создания «всемирной паутины» (на фото слева). Работа над созданием протокола длилась около двух лет и уже в марте 1991 года было начато использование протокола, как механизма для доступа к документам в Интернете и облегчения навигации посредством использования гипертекста.
Самая ранняя версия протокола HTTP/0.9 была впервые опубликована в январе 1992 года. Спецификация протокола привела к упорядочению правил взаимодействия между клиентами и серверами HTTP, а также чёткому разделению функций между этими двумя компонентами. Были задокументированы основные синтаксические и семантические положения.
В мае 1996 года для практической реализации HTTP был выпущен информационный документ RFC 1945, послуживший основой для реализации большинства компонентов более поздней версии HTTP/1.0. И, наконец, в июне 1999 года была принята версия протокола HTTP/1.1, использующаяся и сегодня.
Основой HTTP является технология «клиент-сервер», то есть предполагается существование потребителей (клиентов), которые инициируют соединение и посылают запрос, и поставщиков (серверов), которые ожидают соединения для получения запроса, производят необходимые действия и возвращают обратно сообщение с результатом.
Особенности HTTP
В отличие от других протоколов HTTP устанавливает отдельную TCP-сессию на каждый запрос, но в более поздних версиях протокола было разрешено делать несколько запросов в ходе одной TCP-сессии. Однако браузеры, как правило, запрашивают только страницу и включённые в неё объекты (картинки, каскадные стили и прочее), а затем сразу разрывают TCP-сессию.
Для поддержки авторизованного доступа в протоколе HTTP используются cookies — небольшие фрагменты данных, отправленные веб-сервером и хранимые на компьютере пользователя. Веб-клиент, браузер, при попытке открыть страницу соответствующего сайта пересылает этот фрагмент данных веб-серверу в виде HTTP-запроса. Применяется для сохранения данных на стороне пользователя, на практике обычно используется для:
- аутентификации пользователя;
- хранения персональных предпочтений и настроек пользователя;
- отслеживания состояния сессии доступа пользователя;
- ведения статистики о пользователях.
Такой способ авторизации позволяет сохранить сессию даже после перезагрузки клиента и сервера.
Ещё одной особенностью протокола HTTP перед тем, как передать сами данные, передаёт заголовок «Content-Type: тип/подтип», позволяющую клиенту однозначно определить, каким образом обрабатывать присланные данные. Тогда как при доступе к данным по FTP или по файловым протоколам тип файла (точнее, тип содержащихся в нём данных) определяется по расширению имени файла, что не всегда удобно.
Это особенно важно при работе с CGI-скриптами, когда расширение имени файла указывает не на тип присылаемых клиенту данных, а на необходимость запуска данного файла на сервере и отправки клиенту результатов работы программы, записанной в этом файле. Кроме этого, протокол HTTP позволяет клиенту прислать на сервер параметры, которые будут переданы запускаемому CGI-скрипту
Для этого же в HTML были введены формы.
Все эти особенности протокола HTTP позволили создавать поисковые машины (первой из которых стала AltaVista, созданная фирмой DEC), форумы и Internet-магазины. Это позволило сделать Интернет коммерческой площадкой: появилось множество компаний, основным полем деятельности которых стало предоставление доступа в Интернет (провайдеры) и создание сайтов.
Что такое HTTP/2 и зачем он нужен
Протокол HTTP/1.1 используется с 1999 года и со временем обрел одну существенную проблему. Современные сайты, в отличие от того, что было распространено в 1999-м году, используют множество различных элементов: скрипты на Javascript, стили на CSS, иногда еще и flash-анимацию. При передаче всего этого хозяйства между браузером и сервером создаются несколько соединений.
Протокол HTTP/2 существенно ускоряет открытие сайтов за счет следующих особенностей:
соединения: несколько запросов могут быть отправлены через одно TCP-соединение, и ответы могут быть получены в любом порядке. Отпадает необходимость держать несколько TCP-соединений;
приоритеты потоков: клиент может задавать серверу приоритеты — какого типа ресурсы для него более важны, чем другие;
сжатие заголовка: размер заголовка HTTP может быть сокращен;
push-отправка данных со стороны сервера: сервер может отправлять клиенту данные, которые тот еще не запрашивал, например, на основании данных о том, какую следующую страницу открывают пользователи.
Конкурс Дикси для digital-агентств
Разработайте классную идею в одной из 18 номинаций онлайн-конкурса – и получите возможность реализовать ее с Дикси, выиграть отличные призы от Коссы/Руварда – и получить заслуженное признание рынка.
Идеи и концепции агентств принимаются на конкурс до 7 декабря,
поторопитесь!
Разработка протокола HTTP/2 основывалась на другом протоколе SPDY, который был разработан Google, но компания Google уже объявила о том, что откажется от дальнейшей поддержки SPDY в пользу более многообещающего HTTP/2.
Статусы HTTP
В ответе сервера первое поле это статус обработки запроса, статусы сгруппированы в пять групп и для каждой группы используется код статуса состоящий из трехзначного числа.
- Статусы, которые начинаются на единицу (1ХХ), используются для передачи информационных сообщений.
- Статусы, которые начинаются на двойку (2ХХ), говорят о том, что запрос выполнен успешно, например наиболее популярный статус (200 OK), означает что страница найдена и она передается клиенту.
- Статусы, которые начинаются на тройку (3ХХ), говорят о перенаправлении, например статус 301 — постоянное перенаправление, говорит о том что страница была перемещена на другой адрес и все последующие запросы должны передаваться на этот новый адрес. Статус 307 тоже говорит о перенаправлении, но временном, сейчас доступ к странице можно получить по другому адресу, но через некоторое время необходимо снова обращаться к исходному адресу.
- Статусы, которые начинаются с четверки (4ХХ), говоря о том, что произошла какая-то ошибка на стороне клиента. Чаще всего встречается ошибка 404 — страница, которую запросил клиент не найдена на сервере. Также возможна ошибка 403 доступ к ресурсу, который запросил клиент запрещен и другие ошибки.
- Статусы начинающиеся на пять (5ХХ) говорят об ошибке на стороне сервера, например 500 — внутренняя ошибка сервера.
Стандарты (протокола) обмена информацией
Это тоже название определённых правил, по которым передают сведения между участниками Сети в том или ином случае. Передаваемая кодированная информация становится понятной для всех абонентов благодаря применению таких правил. Обычно к ним относят следующие явления:
- приёмы реализации по контролю;
- структура, по которой удалось построить базы данных и т. д.
Обратите внимание! Надёжность передачи информации повышается, если элементы достаточно сложные. Но скорость обработки из-за этого может уменьшаться
Какой протокол является базовым в Интернете — будет рассмотрено далее.
Важно! Практически каждый разработчик может использовать свои собственные решения. Но подобные системы доступны только ограниченному числу пользователей
Интеграция в сложные сетевые процессы обмена информацией становится недоступной.
Поэтому в международной практике используют варианты, которые можно разделить на две крупные ветки. Это уровень обычных компьютерных сетей и промышленные либо полевые линии связи. Понятие используется на практике достаточно давно.
Загрузка нескольких ресурсов
Посмотрим как это реализуется. Прежде чем, что-то загружать с web-сервера, клиенту необходимо установить TCP соединение.

Затем выполняется запрос по протоколу HTTP.

GET возвращает web-страницу, после этого соединение закрывается.

Браузер анализирует содержимое web-страницы, видит, что необходимо загрузить целевой файл, большое количество картинок и другие элементы. Для того чтобы загрузить следующий ресурс, например стилевой файл необходимо открыть новое соединение.
После этого клиент передает запрос HTTP GET на загрузку стилевого файла.
Сервер в ответ передает этот файл.
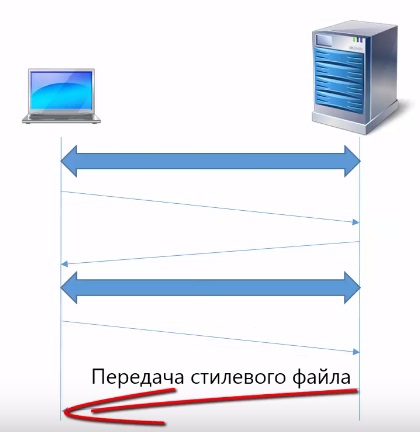
После чего соединение снова закрывается. Таким образом, для того чтобы загрузить каждый элемент web-страницы, необходимо открыть отдельные tcp соединения.
Как работает запрос Conditional GET
При первом обращении к ресурсу, браузер посылает обычный запрос GET и сохраняет результат в кэш. Conditional GET можно использовать только если в http ответе установлен заголовок Last-modified, в котором указана дата последнего изменения ресурса.
В следующий раз, когда браузер будет обращаться к серверу за тем же самым ресурсом, он уже будет использовать запрос Conditional GET, в этом запросе используется дополнительный заголовок if-Modified-Since, в этом заголовки указывается дата изменения ресурсов, это дата как раз берется из значения заголовка last-modified, который передал нам сервер.
Ответ на запрос GET с условием
Сервер может передать два варианта ответа на Conditional GET запрос. Если ресурс не поменялся, то сервер передает короткое сообщение со статусом 304 Not Modified. Это сообщение, также может включать дополнительные заголовки по управлению кэша. Сам ресурс при этом не передается, так как актуальная копия есть в кэше браузера. Если же ресурс поменялся, то измененная версия ресурса передается полностью, при этом используется статус http ответа 200 OK.
ETag в запросах Get с условием
В протоколе версия HTTP 1.1 появилась другая возможность проверить изменился ресурс или нет. Для этого используется entity tag или сокращенно ETag, это код который генерируется на основе содержимого ресурса? как правило это хэш-код или что-нибудь подобное.
Web-сервер при отправке ресурса, добавляет этот код в заголовок ETag, если ресурс изменился, то значение ETag также поменяются. ETag удобно применять, если web-сервер может передавать различные варианты одной и той же страниц.
Например, на разных языках, в этом случае дату изменений использовать нельзя, так как страницы на разных языках могут быть изменены в одно и тоже время, а ETag вполне подходит. Если мы хотим использовать ETag в conditional GET то вместо заголовка if-Modified-Since мы должны указывать If-None-Match. Вот пример: If-None-Match: 57454284-3d8f
Заголовок Cache—Control
В стандарте HTTP 1.1 появился новый заголовок Cache-Control с помощью которого можно более гибко управлять кэшированием. Заголовок Cache-Control может содержать несколько различных элементов.
Cache-Control: private, max-age=10. В этом примере используется два элемента private и max-age = 10 разделенное запятой.
Что можно использовать в заголовке Cache-Control
- значение no-store, говорит о том, что ресурс нельзя сохранять в кэш;
- no-cache, говорит о том, что и ресурсы сохранять в кэш можно, но для его использования необходимо выполнить запрос conditional GET, и загружать ресурс из кэша только в том случае если он не изменился на сервере;
- public, говорит о том, что информация может быть доступна всем и ее можно кэшировать, это значение удобно использовать совместно с http аутентификацией, так как по умолчанию при аутентификации кэширование не используется;
- private сообщает о том, что страница может быть сохранена только в частном кэша браузера, но не в разделяемых кэшах;
- max-age устанавливает время хранения ресурсов кэша в секундах, используется для замены заголовка expires.
3.12 Еденицы измерения диапазонов (Range Units).
HTTP/1.1 позволяет клиенту запрашивать только часть объекта.
HTTP/1.1 использует еденицы измерения диапазонов в полях заголовка
Range () и Content-Range (). Объект может
быть разбит на части соответственно различным структурным модулям.
range-unit = bytes-unit | other-range-unit
bytes-unit = "bytes"
other-range-unit = token
Единственая еденица измерения диапазонов, определенная в HTTP/1.1
— это «bytes». Реализации HTTP/1.1 могут игнорировать диапазоны,
определенные с использованием других едениц измерения. HTTP/1.1
был разработан, чтобы допускать реализации приложений, которые не
зависят от знания диапазонов.
Copyright 1998
Alex Simonoff
(http://www.omsk.com/Leshik/),
All Rights Reserved.
Коды состояния
В ответ на запрос от клиента, сервер отправляет ответ, который содержит, в том числе, и код состояния. Данный код несёт в себе особый смысл для того, чтобы клиент мог отчётливей понять, как интерпретировать ответ:
1xx: Информационные сообщения
Набор этих кодов был введён в HTTP/1.1. Сервер может отправить запрос вида: Expect: 100-continue, что означает, что клиент ещё отправляет оставшуюся часть запроса. Клиенты, работающие с HTTP/1.0 игнорируют данные заголовки.
2xx: Сообщения об успехе
Если клиент получил код из серии 2xx, то запрос ушёл успешно. Самый распространённый вариант — это 200 OK. При GET запросе, сервер отправляет ответ в теле сообщения. Также существуют и другие возможные ответы:
- 202 Accepted: запрос принят, но может не содержать ресурс в ответе. Это полезно для асинхронных запросов на стороне сервера. Сервер определяет, отправить ресурс или нет.
- 204 No Content: в теле ответа нет сообщения.
- 205 Reset Content: указание серверу о сбросе представления документа.
- 206 Partial Content: ответ содержит только часть контента. В дополнительных заголовках определяется общая длина контента и другая инфа.
3xx: Перенаправление
Своеобразное сообщение клиенту о необходимости совершить ещё одно действие. Самый распространённый вариант применения: перенаправить клиент на другой адрес.
- 301 Moved Permanently: ресурс теперь можно найти по другому URL адресу.
- 303 See Other: ресурс временно можно найти по другому URL адресу. Заголовок Location содержит временный URL.
- 304 Not Modified: сервер определяет, что ресурс не был изменён и клиенту нужно задействовать закэшированную версию ответа. Для проверки идентичности информации используется ETag (хэш Сущности — Enttity Tag);
4xx: Клиентские ошибки
Данный класс сообщений используется сервером, если он решил, что запрос был отправлен с ошибкой. Наиболее распространённый код: 404 Not Found. Это означает, что ресурс не найден на сервере. Другие возможные коды:
- 400 Bad Request: вопрос был сформирован неверно.
- 401 Unauthorized: для совершения запроса нужна аутентификация. Информация передаётся через заголовок Authorization.
- 403 Forbidden: сервер не открыл доступ к ресурсу.
- 405 Method Not Allowed: неверный HTTP метод был задействован для того, чтобы получить доступ к ресурсу.
- 409 Conflict: сервер не может до конца обработать запрос, т.к. пытается изменить более новую версию ресурса. Это часто происходит при PUT запросах.
5xx: Ошибки сервера
Ряд кодов, которые используются для определения ошибки сервера при обработке запроса. Самый распространённый: 500 Internal Server Error. Другие варианты:
- 501 Not Implemented: сервер не поддерживает запрашиваемую функциональность.
- 503 Service Unavailable: это может случиться, если на сервере произошла ошибка или он перегружен. Обычно в этом случае, сервер не отвечает, а время, данное на ответ, истекает.
3.2 Универсальные Идентификаторы Ресурсов (URI).
URI известны под многими именами: WWW адреса, Универсальные
Идентификаторы Документов, Универсальные Идентификаторы Ресурсов
(URI), и, в заключение, как комбинация Единообразных Идентификаторов
Ресурса (Uniform Resource Locators, URL) и Единообразных Имен
Ресурса (Uniform Resource Names, URN). HTTP определяет URL просто
как строку определенного формата, которая идентифицирует — через
имя, расположение, или любую другую характеристику — ресурс.
3.2.1 Общий синтаксис.
URI в HTTP могут представляться в абсолютной (absolute) форме или
относительно некоторой известной основы URI (relative), в
зависимости от контекста их использования. Эти две формы
различаются тем, что абсолютные URI всегда начинаются с имени
схемы с двоеточием.
URI = ( absoluteURI | relativeURI )
absoluteURI = scheme ":" *( uchar | reserved )
relativeURI = net_path | abs_path | rel_path
net_path = "//" net_loc
abs_path = "/" rel_path
rel_path =
path = fsegment *( "/" segment )
fsegment = 1*pchar
segment = *pchar
params = param *( ";" param )
param = *( pchar | "/" )
scheme = 1*( ALPHA | DIGIT | "+" | "-" | "." )
net_loc = *( pchar | ";" | "?" )
query = *( uchar | reserved )
fragment = *( uchar | reserved )
pchar = uchar | ":" | "@" | "&" | "=" | "+"
uchar = unreserved | escape
unreserved = ALPHA | DIGIT | safe | extra | national
escape = "%" HEX HEX
reserved = ";" | "/" | "?" | ":" | "@" | "&" | "=" | "+"
extra = "!" | "*" | "'" | "(" | ")" | ","
safe = "$" | "-" | "_" | "."
unsafe = CTL | SP | <"> | "#" | "%" | "<" | ">"
national = <любой OCTET за исключением ALPHA, DIGIT,
reserved, extra, safe, и unsafe>
Полную информацию относительно синтаксиса и семантики URL смотрите
И .
Вышеуказанная нормальная запись
Бекуса-Наура включает национальные символы, недозволенные в
допустимых URL (это определено в , так
как HTTP серверы
позволяют использовать для представления части rel_path адресов
набор незарезервированных символов, и, следовательно, HTTP
прокси-сервера могут получать запросы URI, не соответствующие
RFC 1738.
Протокол HTTP не накладывает a priori никаких ограничений на длины
URI. Серверы ДОЛЖНЫ быть способны обработать URI любого ресурса,
который они обслуживают, и им СЛЕДУЕТ быть в состоянии обрабатывать
URI неограниченной длины, если они обслуживают формы, основанные
на методе GET, которые могут генерировать такой URI. Серверу
СЛЕДУЕТ возвращать код состояния 414 (URI запроса слишком длинный,
Request-URI Too Long), если URI больше, чем сервер может обработать
(смотрите ).
Обратите внимание: Серверы должны быть осторожны с URI, которые
имеют длину более 255 байтов, потому что некоторые старые
клиенты или прокси-сервера не могут правильно поддерживать
эти длины.
3.2.2 HTTP URL.
«Http» схема используется для доступа к сетевым ресурсам при помощи
протокола HTTP. Этот раздел определяет схемо-определенный синтаксис
и семантику для HTTP URL.
http_URL = "http:" "//" host
host = <допустимое доменное имя машины
или IP адрес (в точечно-десятичной форме),
как определено в разделе 2.1 >
port = *DIGIT
Если порт пуст или не задан — используется порт 80. Это означает,
что идентифицированный ресурс размещен в сервере, ожидающем TCP
соединений на специфицированном порте port, компьютера host, и
запрашиваемый URI ресурса — abs_path. Использования IP адресов в
URL СЛЕДУЕТ избегать, когда это возможно (смотрите ).
Если abs_path не представлен в URL, он ДОЛЖЕН рассматриваться как
«/» при вычислении запрашиваемого URI (Request-URI) ресурса
().
3.2.3 Сравнение URI.
При сравнении двух URI, чтобы решить соответствуют ли они друг
другу или нет, клиенту СЛЕДУЕТ использовать чувствительное к
регистру пооктетное (octet-by-octet) сравнение этих URI, со
следующими исключениями:
- Порт, который пуст или не указан, эквивалентен заданному по умолчанию порту для этого URI;
- Сравнение имен хостов ДОЛЖНО производиться без учета регистра;
- Сравнение имен схем ДОЛЖНО производиться без учета регистра;
- Пустой abs_path эквивалентен «/».
Символы, отличные от тех, что находятся в «зарезервированных»
(«reserved») и «опасных» («unsafe») наборах (см. )
эквивалентны их кодированию как «»%» HEX HEX «.
Например следующие три URI эквивалентны:
http://abc.com:80/~smith/home.html
http://ABC.com/%7Esmith/home.html
http://ABC.com:/%7esmith/home.html
Инструменты для просмотра сетевого трафика по HTTP (* поток данных в передающей среде; состоит из передаваемых данных и служебной информации, необходимой для организации их прохождения)
Разработчикам доступно множество инструментов для мониторинга HTTP трафика. Здесь будут перечислены наиболее популярные.
Без сомнений, фаворитом среди веб-разработчиков является инспектор Chrome/Webkit.
Также в их распоряжении имеются прокси для отладки веб-приложений, например, Fiddler (* работает с трафиком между вашим компьютером и удаленным сервером и позволяет просматривать и менять его) для Windows и Charles Proxy для OSX. Мой коллега, Rey Bango, написал замечательную статью на эту тему. Мой коллега, Rey Bango, написал замечательную статью на эту тему.
Из набора программ с интерфейсом командной строки для мониторинга трафика HTTP у нас имеются такие утилиты, как curl, tcpdump и tshark.
Symbols
Формат ответа
Формат ответа отличается только статусом и рядом заголовков. Статус выглядит так:
Status-Line = HTTP-Version SP Status-Code SP Reason-Phrase CRLF
- HTTP версия
- Код статуса
- Сообщение статуса, понятное для человека
Обычный статус выглядит примерно так:
HTTP/1.1 200 OK
Заголовки ответа могут быть следующими:
response-header = Accept-Ranges
| Age
| ETag
| Location
| Proxy-Authenticate
| Retry-After
| Server
| Vary
| WWW-Authenticate
- Age время в секундах, когда сообщение было создано на сервере.
- ETag MD5 сущности для проверки изменений и модификаций ответа.
- Location используется для перенаправления и содержит новый URL адрес.
- Server определяет сервер, где было сформирован ответ.
Думаю, на сегодня теории достаточно. Теперь давайте взглянем на инструменты, которыми мы можем пользоваться для мониторинга HTTP сообщений.
Библиотеки для работы с HTTP — jQuery AJAX
Поскольку jQuery очень популярен, в нём также есть инструментарий для обработки HTTP ответов при AJAX запросах. Информацию о jQuery.ajax(settings) можете найти на официальном сайте.
Передав объект настроек (settings), а также воспользовавшись функцией обратного вызова beforeSend, мы можем задать заголовки запроса, с помощью метода setRequestHeader().
$.ajax({
url: 'http://www.articles.com/latest',
type: 'GET',
beforeSend: function (jqXHR) {
jqXHR.setRequestHeader('Accepts-Language', 'en-US,en');
}
});
Прочитать объект jqXHR можно с помощью метода jqXHR.getResponseHeader().
Если хотите обработать статус запроса, то это можно сделать так:
$.ajax({
statusCode: {
404: function() {
alert("page not found");
}
}
});