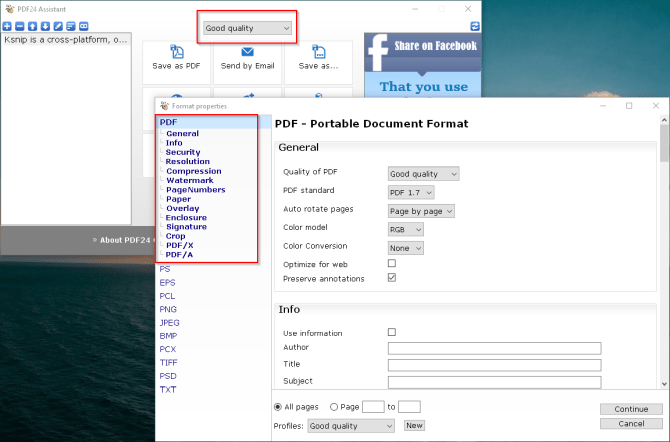
Что такое xml
Содержание:
Просмотр через браузер
Если на компьютере вдруг не оказалось ни одного текстового редактор, или XML не открывается в читаемом виде, можно воспользоваться браузером или посмотреть содержимое файла онлайн.
Браузеры
Все современные браузеры поддерживают чтение формата XML. Однако нужно понимать, что раз в документе нет сведений о том, как отображать данные, веб-обозреватели показывают их «как есть». Чтобы использовать для открытия браузер (на примере Chrome):
- Щелкните правой кнопкой по XML-файлу. Выберите «Открыть с помощью».
- Если веб-обозревателя нет в списке приложений, которые можно использовать для просмотра файла, нажмите «Выбрать программу».
- Если в появившемся окне тоже не будет обозревателя, кликните по кнопке «Обзор».
- Пройдите к исполняемому файлу обозревателя в папке Program Files (Chrome по умолчанию устанавливается в этот каталог, но если вы меняли место инсталляции, то используйте другой путь).
- Выберите chrome.exe и нажмите «ОК».
Аналогичным образом запуск выполняется через другие браузеры. В обозревателе откроется новая вкладка, внутри которой отобразится содержимое документа XML.
В Mozilla Forefox можно открыть файл другим способом:
- Щелкните правой кнопкой по верхней панели. Отметьте пункт «Панель меню».
- Раскройте раздел «Файл». Нажмите «Открыть файл».
- Найдите документ XML через проводник и нажмите «Открыть».
Если файл поврежден, то браузер при попытке открыть документ может вывести сообщение об ошибке. В таком случае рекомендуется воспользоваться одним из редакторов XML, указанных выше.
Онлайн-сервис
Просмотреть и отредактировать XML-файл можно на онлайн-сервисе xmlgrid.net. Порядок работы такой:
- Откройте страничку онлайн-редактора, нажмите «Open File».
- Щелкните по кнопке «Выберите файл» и укажите путь к документу. Нажмите «Submit».
На странице отобразится содержимое документа. Вы можете его просматривать и редактировать прямо в окне браузера. Есть и другие онлайн-сервисы — например, CodeBeautify, XML Editor от TutorialsPoint. Так что файл XML при любом раскладе будет прочитан и отредактирован, если у пользователя возникнет такое желание.
Users
List of some applications/projects using Fast XML Parser. (Raise an issue to submit yours)
Main Features
- Validate XML data syntactically
- Transform XML to JSON or Nimn
- Transform JSON back to XML
- Works with node packages, in browser, and in CLI (press try me button above for demo)
- Faster than any pure JS implementation.
- It can handle big files (tested up to 100mb).
- Various options are available to customize the transformation
- You can parse CDATA as a separate property.
- You can prefix attributes or group them to a separate property. Or they can be ignored from the result completely.
- You can parse tag’s or attribute’s value to primitive type: string, integer, float, hexadecimal, or boolean. And can optionally decode for HTML char.
- You can remove namespace from tag or attribute name while parsing
- It supports boolean attributes, if configured.
Метод 2: использование BeautifulSoup (надежный)
Это также еще один хороший выбор, если по какой-то причине исходный XML плохо отформатирован. XML может работать не очень хорошо, если вы не выполните предварительную обработку файла.
Оказывается, BeautifulSoup очень хорошо работает со всеми этими типами файлов, поэтому, если вы хотите проанализировать любой XML-файл, используйте этот подход.
Чтобы установить его, используйте и установите модуль :
pip3 install bs4
Я дам вам небольшой фрагмент нашего предыдущего XML-файла:
<data>
<items>
<item name="item1">10</item>
<item name="item2">20</item>
<item name="item3">30</item>
<item name="item4">40</item>
</items>
</data>
Я передам этот файл, а затем его с помощью .
from bs4 import BeautifulSoup
fd = open('sample.xml', 'r')
xml_file = fd.read()
soup = BeautifulSoup(xml_file, 'lxml')
for tag in soup.findAll("item"):
# print(tag)
print(tag)
print(tag.text)
fd.close()
Синтаксис аналогичен нашему модулю , поэтому мы по-прежнему получаем имена атрибутов, используя и . Точно так же, как и раньше!
Выход
item1 10 item2 20 item3 30 item4 40
Мы также проанализировали это с помощью ! Если ваш исходный файл плохо отформатирован, можно использовать этот метод, поскольку BeautifulSoup имеет другие правила для обработки таких файлов.
Что такое XML формат
XML расшифровуется как Extensible Markup Language, с акцентом на второе слово. Здесь можно создавать текст и размечать его тегами, превращая слово или фрагмент в отсортированную информацию. Все эти элементы обрабатываются в электронном варианте и применяются с целью распределения текста. Чем их больше, тем больше частей можно идентифицировать. В XML можно создавать перечень своих элементов в Описании типа документа (Document Type Definition — DTD) и придерживаться его при работе с файлом. С использованием такой разметки потеря бумажного носителя не влечет серьезных последствий. Все данные останутся в первоначальном виде в электронном варианте.
Online XML viewer
One of the most widely used and powerful tool to represent a data is XML. The language is bounded by a set of rules which allows lets it to represent any complex data. All the names are supposed to begin with a letter, colon(;) or an underscore (_), and the language must be continued with a set of acceptable symbols for names, which can include dashes, dots, Arabic digits, punctuation marks and many more.
Now a days, XML syntax have made its way to the default Microsoft programs and tools such as, Microsoft Office, LibreOffice, OpenOffice.org and also in iWork of Apple. Not only this but Apple also uses XML for their implementation of registry. Another insight to highlight the major usage of XML is even the XHTML document format uses the XML syntax.
How is XML viewer helpful?
So how the online XML viewer helps you? The user can use the tool to format and improve or beautify your XML. The tool also enables the user to view the XML in a tree view which makes it easier to understand and read. By using the view online XML tool; you can validate and check your XML, as any discrepancies will be highlighted as an error. The XML can be loaded from any url too and can also be converted to JSON format.
XML TO JSON Convertor
The JSON format has gained a name in the data formatting and has been widely used in several AJAX operated websites. JSON is basically a text format, highly used in JavaScript. If compared to XML text format, then JSON is preferred to be more convenient for representation of complex data. It allows the data to also be presented as pairs like: ‘key’-> ‘value’ . JSON format — is the text format, which is based on Javascript syntax and used to declare object data.
There are a number of websites that offer API’s and return the data in JSON format. This formatting also lets to reduce the data size being transferred with a whitespace compressed feature.
The online XML viewer is an user friendly tool which only represents the text input by user if it successfully parses XML, otherwise, the tool shows an error and doesn’t represents anything. As a user friendly feature, the view XML online tool also has a variant to convert he XML data to JSON which can also be further manipulated.
When the user uses the view XML online tool, it also extends to convert the XML data to JSON, which can also be done either by loading a XML URL or converting directly by opening a XML file from your PC. The JSON data can easily be converted by to XML format too. And likewise, if any discrepancies are made while formatting, the JSON doesn’t parse and no visualization is done, alerting the user with an error. For user’s ease, the JSON data can also be viewed in a tree view, adding a little beauty to the text.
Intelligent XML editing
Advanced content completion support offers a context-sensitive list of XML
elements, attributes, and values and is driven by XML Schema, Relax NG, NVDL, DTD, or
the document structure
Easily edit XML documents with repetitive patterns using the XML Grid Editing
Mode
Schema annotations/DTD comments are presented in a documentation window next to
the content completion proposals
Editing and validation support for NVDL scripts and XML documents associated with
NVDL
Quickly insert using the Content Completion Assistant
Powerful tree-based XML Outline
view, synchronized in real time with the edited document
New XML file wizards allow you to easily create XML documents that specify a
schema or DTD
Quick Assist and Quick Fix support helps you to quickly resolve errors in XML
documents
presents schema
information about the current XML element
Редактор XML
XML Marker is an XML and Json Editor that uses a synchronized table-tree-and-text display to show you both the hierarchical and the tabular nature of your XML data.
It automatically produces a tabular display of any selected tag by collecting repeating attribute and tag names and then arranging them into columns. The result is a clutter-free and informative tabular display.
The implementation is very efficient in memory and CPU resources so you can quickly navigate through very large XML files – up to about 500 megabytes.
More features include table sorting, syntax-highlighting editor, automatic indentation/pretty-printing of exiting code, drill down, as-you-type syntax checking, bookmarks, convert to spreadsheet, Branch Selector, non-collapsing editing and more.
XML Marker have full internationalization support with both Unicode/utf-8 and code page encoding.
Login to post comments
Copyright 2003 — 2018 by symbol click. Contact info
|
||
|
Evladar 28.08.14 — 11:04 |
Если у кого была такая задача, подскажите методику. Знаю, что XML-файл можно открыть или на запись, или на чтение.Но необходимо открыть XML-файл, найти значение атрибута по имени и поменять в случае необходимости.То есть, открыть, исправить и записать. Как это сделать (открыть на перезапись)? |
|
|
Ёпрст 1 — 28.08.14 — 11:20 |
Открыть блокнотом и исправить |
|
|
Evladar 2 — 28.08.14 — 11:25 |
(1) Когда будет тысяча строк, обращусь за помощью ) |
|
|
ДенисЧ 3 — 28.08.14 — 11:25 |
поставить нормальные редактор XML |
|
|
Ёпрст 4 — 28.08.14 — 11:26 |
(2) Не вопрос, найти и заменить в любом текстовом редакторе пока еще никто не отменял |
|
|
Evladar 5 — 28.08.14 — 11:27 |
Народ, давайте, по существу ) |
|
|
ДенисЧ 6 — 28.08.14 — 11:29 |
(5) не тупи. Тебе уже ответили. |
|
|
Эльниньо 7 — 28.08.14 — 11:29 |
Не нравится блокнот — открой вордом и удивись |
|
|
Evladar 8 — 28.08.14 — 11:29 |
Я думаю, считать из файла, например, в ТЗ или в какую-либо другую структуру, сделать изменения, открыть на запись и залить целиком туда. Но это долго.Ищу вариант попроще. |
|
|
Evladar 9 — 28.08.14 — 11:30 |
Ну, вы что, каким блокнотом? ))У меня тысяча строк, и мне надо дату увеличить на 1 день в определённом атрибуте. | |
|
Любопытная 10 — 28.08.14 — 11:31 |
(9) и в чем проблема? |
|
|
Evladar 11 — 28.08.14 — 11:35 |
(1) Надо посадить пользователя сделать 1000 изменений в блокноте исправлением разных дат. Вместо нажатия одной кнопки.Какая может быть проблема?) |
|
|
Ёпрст 12 — 28.08.14 — 11:36 |
(9) и чего ?читаешь один файл, пишешь в другой, можешь тупо по-строчно, вообще без всяких структур и дом-документов |
|
|
Evladar 13 — 28.08.14 — 11:37 |
(12)Вот и я думаю, можно ли проще.Ладно, ясно. |
|
|
Мыш 14 — 28.08.14 — 11:42 |
ТекстовыйДокумент.ЗаменитьСтроку(НомерСтроки, Строка); |
|
|
mistеr 15 — 28.08.14 — 11:55 |
(0) Основных варианта два. 1. Считать в DOM, найти элемент, исправить, записать. Минусы: внешний вид на выходе может отличаться. 2. Считать как текст, найти нужное место поиском, заменить, записать. Минусы: можно ошибиться с поиском. |
|
|
hovnokoder 16 — 28.08.14 — 12:04 |
Я делал так:
НовИмяф=Лев(имяф,(СтрДлина(имяф)-3))+»xml»; ТВ=СоздатьОбъект(«Текст»); ТВ.Открыть(«D:\mail\»+имяф); Стр1=ТВ.ПолучитьСтроку(1); Если Найти(Стр1,»utf-8″)>0 Тогда Стр1=СтрЗаменить(Стр1,»utf-8″,»WINDOWS-1251»); ТВ.ЗаменитьСтроку(1,Стр1); ТВ.Записать(«D:\mail\»+НовИмяф); Фс.УдалитьФайл(«D:\mail\»+имяф);……. |
TurboConf 5 — расширение возможностей Конфигуратора 1С
ВНИМАНИЕ! Если вы потеряли окно ввода сообщения, нажмите Ctrl-F5 или Ctrl-R или кнопку «Обновить» в браузере. Тема не обновлялась длительное время, и была помечена как архивная
Добавление сообщений невозможно. Но вы можете создать новую ветку и вам обязательно ответят! Каждый час на Волшебном форуме бывает более 2000 человек
Тема не обновлялась длительное время, и была помечена как архивная. Добавление сообщений невозможно. Но вы можете создать новую ветку и вам обязательно ответят! Каждый час на Волшебном форуме бывает более 2000 человек.
Чем ещё предлагала система открыть файл XML?
Программу WordPad. Эта программа похожа на урезанный Word программ «Office», только системный. Итак, открываем программой WordPad. Как видно из скриншота, текстовая часть кода та же, но, возможности меню увеличены. Хотя, для данного файла они лишние.
Чем ещё предлагала система открыть файл? Обычным Word. Итак, открываем файл этим текстовым редактором. Как видим, программа Word преобразила коды в настоящие ссылки и даты, которые закодированы в этом файле. Я думаю, части пользователей такой вариант открытия файла кажется боле удобным. Как по мне, более понятно, когда видишь вариант кода таким, какой он есть, чем преображенный. То есть, лучше всего файл с расширением XML открывает программа «Notepad++».
Парсинг на примере книги
Что-ж, результат нашего примера немного скучный. Большую часть времени, вам нужно будет сохранить извлеченные данные, и сделать с ними что-нибудь, а не просто вывести его в stdout. Так что в следующем нашем примере мы создадим структуру данных для сбора результатов. В данном примере структура наших данных будет представлять собой список словарей. Мы используем пример книги MSDN. Сохраните следующий код XML под названием example.xml.
Python
<?xml version=»1.0″?>
<catalog>
<book id=»bk101″>
<author>Gambardella, Matthew</author>
<title>XML Developer’s Guide</title>
<genre>Computer</genre>
<price>44.95</price>
<publish_date>2000-10-01</publish_date>
<description>An in-depth look at creating applications
with XML.</description>
</book>
<book id=»bk102″>
<author>Ralls, Kim</author>
<title>Midnight Rain</title>
<genre>Fantasy</genre>
<price>5.95</price>
<publish_date>2000-12-16</publish_date>
<description>A former architect battles corporate zombies,
an evil sorceress, and her own childhood to become queen
of the world.</description>
</book>
<book id=»bk103″>
<author>Corets, Eva</author>
<title>Maeve Ascendant</title>
<genre>Fantasy</genre>
<price>5.95</price>
<publish_date>2000-11-17</publish_date>
<description>After the collapse of a nanotechnology
society in England, the young survivors lay the
foundation for a new society.</description>
</book>
</catalog>
|
1 |
<?xml version=»1.0″?> <catalog> <book id=»bk101″> <author>Gambardella,Matthew<author> <title>XMLDeveloper’sGuide<title> <genre>Computer<genre> <price>44.95<price> <publish_date>2000-10-01<publish_date> <description>An in-depth look at creating applications withXML.<description> <book> <book id=»bk102″> <author>Ralls,Kim<author> <title>Midnight Rain<title> <genre>Fantasy<genre> <price>5.95<price> <publish_date>2000-12-16<publish_date> <description>Aformer architect battles corporate zombies, an evil sorceress,andher own childhood to become queen of the world.<description> <book> <book id=»bk103″> <author>Corets,Eva<author> <title>Maeve Ascendant<title> <genre>Fantasy<genre> <price>5.95<price> <publish_date>2000-11-17<publish_date> <description>After the collapse ofananotechnology society inEngland,the young survivors lay the foundation foranewsociety.<description> <book> <catalog> |
Теперь мы выполним парсинг данного XML и вставим его в нашу структуру данных!
Python
# -*- coding: utf-8 -*-
from lxml import etree
def parseBookXML(xmlFile):
with open(xmlFile) as fobj:
xml = fobj.read()
root = etree.fromstring(xml)
book_dict = {}
books = []
for book in root.getchildren():
for elem in book.getchildren():
if not elem.text:
text = «None»
else:
text = elem.text
print(elem.tag + » => » + text)
book_dict = text
if book.tag == «book»:
books.append(book_dict)
book_dict = {}
return books
if __name__ == «__main__»:
parseBookXML(«books.xml»)
|
1 |
# -*- coding: utf-8 -*- fromlxml importetree defparseBookXML(xmlFile) withopen(xmlFile)asfobj xml=fobj.read() root=etree.fromstring(xml) book_dict={} books= forbook inroot.getchildren() forelem inbook.getchildren() ifnotelem.text text=»None» else text=elem.text print(elem.tag+» => «+text) book_dictelem.tag=text ifbook.tag==»book» books.append(book_dict) book_dict={} returnbooks if__name__==»__main__» parseBookXML(«books.xml») |
Данный пример весьма похож на предыдущий, так что мы сосредоточимся только на различиях между ними. Перед началом итерации над контекстом, мы создадим объект пустого словаря и пустой список Python. Далее, в цикле, мы создадим наш словарь вот так:
Python
book_dict = text
| 1 | book_dictelem.tag=text |
Текст может быть как elem.text так и None. Наконец, если тег окажется книгой, тогда мы в конце книжной секции, и нам нужно добавить словарь в наш список, а также сбросить словарь для следующей книги. Как мы видим, это именно то, что мы сделали. Более реалистичным примером будет размещение извлеченных данных в Python класс Book. Ранее я делал последнее с json feeds. Теперь мы готовы к тому, чтобы приступить к парсингу XML с lxml.objectify!
Чем ещё можно открыть подобный файл XML?
Как я уже сказал, такие файлы содержать текст. Отсюда, попробуем открыть данный файл самым простым текстовым редактором «Блокнот». Итак, опять попробуем открыть файл sitemap.xml. Кликнем по файлу правой кнопкой мышки. Выберем «Открыть с помощью» и среди программ ниспадающего меню, выберем «блокнот».
Теперь, мы уже видим структуру кода данного документа. Вам понятно, что этот код означает? Мне да. В файле идёт перечисление адресов статей моего сайта, времени их написания, и прочее.
Итак, давайте вспомним, чем ещё предлагала система открыть данные файлы? Одной из лучших программ для этого, на мой взгляд, является бесплатная русифицированная программа просмотра файлов сайта «Notepad++» (эта программа очень похожа на Блокнот). Скачать Notepad++ https://notepad-plus-plus.org/download/v7.6.html с официального сайта. Затем, во время установки, если вы увидите, что дизайн идёт английский, не забудьте поменять его на русский!
Как вы заметили, данная программа имеет, по сравнению с блокнотом, более богатый функционал, включавший разнообразное меню, вроде «Кодировки», «Инструменты», «Макросы», «Поиск» и прочее. Да и сам код файла выглядит более красиво. Различные части кода отмечены разным цветом.
Если же «Notepad++» открывает письма с крякозябрами, то, это значит, их нужно перевести в нормально читаемый формат. Для этого, откроем «Notepad++». В меня выбираем «Кодировки», затем выберем «Кодировка в UTF-8 без BOM». Теперь в данном редакторе, у вас должен открыться человеко читаемый формат!