Python array
Содержание:
- 1.1. Автозаполнение массивов
- Ввод списка (массива) в языке Питон
- Операции на массиве
- Индексирование массивов
- Python Tutorial
- Обработка элементов двумерного массива
- Модуль array определяет следующий тип:
- Обработка текста в NumPy на примерах
- Массив нарезки
- Манипуляции с формой
- Примеры работы с NumPy
- Создание массивов
- Многомерный массив
- Двумерные массивы
- Начинаем работу
- Как создаются матрицы в Python?
- Глубокое и поверхностное копирование объектов с помощью copy
- Использование sorted() для итерируемых объектов Python
- Ways to Print an Array in Python
- Добавление нового массива
1.1. Автозаполнение массивов
- Возвращает новый массив заданной формы и типа без инициированных записей.
- Возвращает новый массив с формой и типом данных указанного массива без инициированных записей.
- Возвращает новый массив в котором диагональные элементы равны единице, а все остальные равны нулю.
- Возвращает новый квадратный массив с единицами по главной диагонали.
- Возвращает новый массив заданной формы и типа, заполненный единицами.
- Возвращает новый массив с формой и типом данных указанного массива, заполненный единицами.
- Возвращает новый массив заданной формы и типа, заполненный нулями.
- Возвращает новый массив с формой и типом данных указанного массива, заполненный нулями.
- Возвращает новый массив заданной формы и типа все элементы которого равны указанному значению.
- Возвращает новый массив с формой и типом данных указанного массива, все элементы которого равны указанному значению.
Ввод списка (массива) в языке Питон
- Простой вариант ввода списка и его вывода:
L= L = int(input()) for i in range(5) # при вводе 1 2 3 4 5 print (L) # вывод: 1 2 3 4 5 |
Функция int здесь используется для того, чтобы строка, введенная пользователем, преобразовывалась в целые числа.
Как уже рассмотрено выше, список можно выводить целым и поэлементно:
# вывод целого списка (массива) print (L) # поэлементный вывод списка (массива) for i in range(5): print ( Li, end = " " ) |
Задание Python 4_7:
Необходимо задать список (массив) из шести элементов; заполнить его вводимыми значениями и вывести элементы на экран. Использовать два цикла: первый — для ввода элементов, второй — для вывода.
Замечание: Для вывода через «,» используйте следующий синтаксис:
print ( Li, end = ", " ) |
Пример результата:
введите элементы массива: 3.0 0.8 0.56 4.3 23.8 0.7 Массив = 3, 0.8, 0.56, 4.3, 23.8, 0.7
Задание Python 4_8:
Заполните список случайными числами в диапазоне 20..100 и подсчитайте отдельно число чётных и нечётных элементов. Использовать цикл.
Замечание: .
Задание Python 4_9: Найдите минимальный элемент списка. Выведите элемент и его индекс. Список из 10 элементов инициализируйте случайными числами. Для перебора элементов списка использовать цикл.
Пример результата:
9 5 4 22 23 7 3 16 16 8 Минимальный элемент списка L7=3 |
Операции на массиве
Еще ряд полезных операций с массивами:
(на всякий случай повторю, чтобы было легче найти) — элемент массива с номером .
(на всякий случай повторю, чтобы было легче найти) — длина массива.
— приписывает к массиву новый элемент со значением , в результате длина массива становится на 1 больше. Конечно, вместо x может быть любое арифметическое выражение.
— симметричная операция, удаляет последний элемент из массива. Длина массива становится на 1 меньше. Если нужно запомнить значение удаленного элемента, надо просто сохранить результат вызова в новую переменную: .
— это массив, полученный приписыванием массива самого к себе три раза. Например, — это . Конечно, на месте тройки тут может быть любое арифметическое выражение. Самое частое применение этой конструкции — если вам нужен массив длины , заполненный, например, нулями, то вы пишете .
— присваивание массивов. Теперь в записан тот же массив, что и в . Тот же — в прямом смысле слова: теперь и , и соответствуют одному и тому же массиву, и изменения в отразятся в и наоборот
Еще раз, потому что это очень важно. Присваивание массивов (и вообще любых сложных объектов) в питоне не копирует массив, а просто обе переменные начинают ссылаться на один и тот же массив, и изменения массива через любую из них меняет один и тот же массив
При этом на самом деле тут есть многие тонкости, просто будьте готовы к неожиданностям.
(«срез») — делает новый массив, состоящий из элементов старого массива начиная со первого (помните про нумерацию с нуля!) и заканчивая третьим (т.е. до четвертого, но не включительно, аналогично тому, как работает ); этот массив сохраняется в . Для примера выше получится . Конечно, на месте 1 и 4 может быть любое арифметическое выражение. Более того, эти индексы можно вообще не писать, при этом автоматически подразумевается начало и конец массива. Например, — это первые три элемента массива (нулевой, первый и второй), — все элементы кроме нулевого, — все элементы кроме последнего (!), а — это копия всего массива. И это именно копия, т.е. запись именно копирует массив, получающиеся массивы никак не связаны, и изменения в не влияют на (в отличие от ).
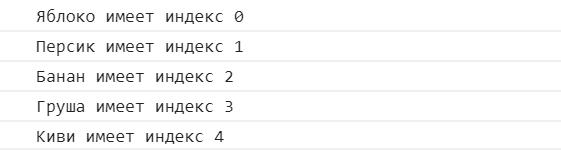
Индексирование массивов
Когда ваши данные представлены с помощью массива NumPy, вы можете получить к ним доступ с помощью индексации.
Давайте рассмотрим несколько примеров доступа к данным с помощью индексации.
Одномерное индексирование
Как правило, индексирование работает так же, как вы ожидаете от своего опыта работы с другими языками программирования, такими как Java, C # и C ++.
Например, вы можете получить доступ к элементам с помощью оператора скобок [], указав индекс смещения нуля для значения, которое нужно получить.
При выполнении примера печатаются первое и последнее значения в массиве.
Задание целых чисел, слишком больших для границы массива, приведет к ошибке.
При выполнении примера выводится следующая ошибка:
Одно из ключевых отличий состоит в том, что вы можете использовать отрицательные индексы для извлечения значений, смещенных от конца массива.
Например, индекс -1 относится к последнему элементу в массиве. Индекс -2 возвращает второй последний элемент вплоть до -5 для первого элемента в текущем примере.
При выполнении примера печатаются последний и первый элементы в массиве.
Двумерное индексирование
Индексация двумерных данных аналогична индексации одномерных данных, за исключением того, что для разделения индекса для каждого измерения используется запятая.
Это отличается от языков на основе C, где для каждого измерения используется отдельный оператор скобок.
Например, мы можем получить доступ к первой строке и первому столбцу следующим образом:
При выполнении примера печатается первый элемент в наборе данных.
Если нас интересуют все элементы в первой строке, мы можем оставить индекс второго измерения пустым, например:
Это печатает первый ряд данных.
Python Tutorial
Python HOMEPython IntroPython Get StartedPython SyntaxPython CommentsPython Variables
Python Variables
Variable Names
Assign Multiple Values
Output Variables
Global Variables
Variable Exercises
Python Data TypesPython NumbersPython CastingPython Strings
Python Strings
Slicing Strings
Modify Strings
Concatenate Strings
Format Strings
Escape Characters
String Methods
String Exercises
Python BooleansPython OperatorsPython Lists
Python Lists
Access List Items
Change List Items
Add List Items
Remove List Items
Loop Lists
List Comprehension
Sort Lists
Copy Lists
Join Lists
List Methods
List Exercises
Python Tuples
Python Tuples
Access Tuples
Update Tuples
Unpack Tuples
Loop Tuples
Join Tuples
Tuple Methods
Tuple Exercises
Python Sets
Python Sets
Access Set Items
Add Set Items
Remove Set Items
Loop Sets
Join Sets
Set Methods
Set Exercises
Python Dictionaries
Python Dictionaries
Access Items
Change Items
Add Items
Remove Items
Loop Dictionaries
Copy Dictionaries
Nested Dictionaries
Dictionary Methods
Dictionary Exercise
Python If…ElsePython While LoopsPython For LoopsPython FunctionsPython LambdaPython ArraysPython Classes/ObjectsPython InheritancePython IteratorsPython ScopePython ModulesPython DatesPython MathPython JSONPython RegExPython PIPPython Try…ExceptPython User InputPython String Formatting
Обработка элементов двумерного массива
Нумерация элементов двумерного массива, как и элементов одномерного массива, начинается с нуля.
Т.е. — это элемент третьей строки четвертого столбца.
Пример обработки элементов матрицы:
Найти произведение элементов двумерного массива.
Решение:
1 2 3 4 5 |
p = 1
for i in range(N):
for j in range(M):
p *= matrixij
print (p)
|
Пример:
Найти сумму элементов двумерного массива.
Решение:
Более подходящий вариант для Python:
1 2 3 4 |
s = for row in matrix: s += sum(row) print (s) |
Для поиска суммы существует стандартная функция sum.
Задание Python 8_0:
Получены значения температуры воздуха за 4 дня с трех метеостанций, расположенных в разных регионах страны:
| Номер станции | 1-й день | 2-й день | 3-й день | 4-й день |
|---|---|---|---|---|
| 1 | -8 | -14 | -19 | -18 |
| 2 | 25 | 28 | 26 | 20 |
| 3 | 11 | 18 | 20 | 25 |
Т.е. запись показаний в двумерном массиве выглядела бы так:
| t:=-8; | t:=-14; | t:=-19; | t:=-18; |
| t:=25; | t:=28; | t:=26; | t:=20; |
| t:=11; | t:=18; | t:=20; | t:=25; |
- Распечатать температуру на 2-й метеостанции за 4-й день и на 3-й метеостанции за 1-й день.
- Распечатать показания термометров всех метеостанций за 2-й день.
- Определить среднюю температуру на 3-й метеостанции.
- Распечатать, в какие дни и на каких метеостанциях температура была в диапазоне 24-26 градусов тепла.
Задание Python 8_1:
Написать программу поиска минимального и максимального элементов матрицы и их индексов.
Задание Python 8_2:
Написать программу, выводящую на экран строку матрицы, сумма элементов которой максимальна.
Для обработки элементов квадратной матрицы (размером N x N):
Для элементов главной диагонали достаточно использовать один цикл:
for i in range(N): # работаем с matrix |
Для элементов побочной диагонали:
for i in range(N): # работаем с matrix |
Пример:Переставить 2-й и 4-й столбцы матрицы. Использовать два способа.
Решение:
-
for i in range(N): c = Ai2 Ai2 = Ai4 Ai4 = c
-
for i in range(N): Ai2, Ai4 = Ai4, Ai2
Задание Python 8_3:
Составить программу, позволяющую с помощью датчика случайных чисел сформировать матрицу размерностью N. Определить:
минимальный элемент, лежащий ниже побочной диагонали;
произведение ненулевых элементов последней строки.
Модуль array определяет следующий тип:
Класс создает новый массив, элементы которого ограничены и инициализируется из необязательного значения , которое должно быть списком, байтоподобным объектом или итерируемым по элементам объектом соответствующего типа.
Если задан список или строка, то инициализатор передается методу , или нового массива для добавления начальных элементов в массив. В противном случае итеративный инициализатор передается в метод .
Создание экземпляра вызывает событие аудита с аргументами , .
Смотрите какие методы определяет класс в разделе «Методы и свойства класса «.
Объекты класса поддерживают общие операции c последовательностями, такие как индексация, срез, объединение и т. д. При использовании среза, назначенное значение должно быть объектом массива с тем же . Во всех остальных случаях вызывается исключение .
Объекты массива также реализуют интерфейс буфера и могут использоваться везде, где поддерживаются байтообразные объекты.
Когда объект класса выводится на печать или преобразуется в строку, он представляется как .
- Инициализатор опускается, если массив пустой.
- Если тип равен , то это строка.
- Во всех остальных случаях это список чисел.
Строка гарантированно может быть преобразована обратно в массив с тем же типом и значением, используя функцию если класс был импортирован с использованием конструкции .
Примеры использования:
>>> from array import array
>>> arr = array('l')
>>> arr
# array('l')
>>> arr = array('u', 'hello \u2641')
>>> arr
# array('u', 'hello ♁')
>>> arr = array('b', b'is array')
>>> arr
# array('b', )
>>> arr = array('l', 1, 2, 3, 4, 5])
>>> arr
# array('l', )
>>> arr = array('d', 1.0, 2.0, 3.14])
>>> arr
# array('d', )
>>> str(arr)
# "array('d', )"
>>> print(arr)
# array('d', )
Обработка текста в NumPy на примерах
Когда дело доходит до текста, подход несколько меняется. Цифровое представление текста предполагает создание некого , то есть инвентаря всех уникальных слов, которые бы распознавались моделью, а также векторно (embedding step). Попробуем представить в цифровой форме цитату из стихотворения арабского поэта Антара ибн Шаддада, переведенную на английский язык:
“Have the bards who preceded me left any theme unsung?”
Перед переводом данного предложения в нужную цифровую форму модель должна будет проанализировать огромное количество текста. Здесь можно обработать небольшой набор данный, после чего использовать его для создания словаря из 71 290 слов.
Предложение может быть разбито на массив токенов, что будут словами или частями слов в зависимости от установленных общих правил:
Затем в данной таблице словаря вместо каждого слова мы ставим его :
Однако данные все еще не обладают достаточным количеством информации о модели как таковой. Поэтому перед передачей последовательности слов в модель токены/слова должны быть заменены их векторными представлениями. В данном случае используется 50-мерное векторное представление Word2vec.
Здесь ясно видно, что у массива NumPy есть несколько размерностей . На практике все выглядит несколько иначе, однако данное визуальное представление более понятно для разъяснения общих принципов работы.
Для лучшей производительности модели глубокого обучения обычно сохраняют первую размерность для пакета. Это происходит из-за того, что тренировка модели происходит быстрее, если несколько примеров проходят тренировку параллельно. Здесь особенно полезным будет . Например, такая модель, как BERT, будет ожидать ввода в форме: .
Теперь мы получили числовой том, с которым модель может работать и делать полезные вещи. Некоторые строки остались пустыми, однако они могут быть заполнены другими примерами, на которых модель может тренироваться или делать прогнозы.
(На заметку: Поэма, строчку из которой мы использовали в примере, увековечила своего автора в веках. Будучи незаконнорожденным сыном главы племени от рабыни, Антара ибн Шаддан мастерски владел языком поэзии. Вокруг исторической фигуры поэта сложились мифы и легенды, а его стихи стали частью классической арабской литературы).
Массив нарезки
Все идет нормально; Создание и индексация массивов выглядит знакомо.
Теперь мы подошли к нарезке массивов, и это одна из функций, которая создает проблемы для начинающих массивов Python и NumPy.
Структуры, такие как списки и массивы NumPy, могут быть нарезаны. Это означает, что подпоследовательность структуры может быть проиндексирована и извлечена.
Это наиболее полезно при машинном обучении при указании входных и выходных переменных или разделении обучающих строк из строк тестирования.
Нарезка задается с помощью оператора двоеточия ‘:’ с ‘от’ а также ‘в‘Индекс до и после столбца соответственно. Срез начинается от индекса «от» и заканчивается на один элемент перед индексом «до».
Давайте рассмотрим несколько примеров.
Одномерная нарезка
Вы можете получить доступ ко всем данным в измерении массива, указав срез «:» без индексов.
При выполнении примера печатаются все элементы в массиве.
Первый элемент массива можно разрезать, указав фрагмент, который начинается с индекса 0 и заканчивается индексом 1 (один элемент перед индексом «до»)
Выполнение примера возвращает подмассив с первым элементом.
Мы также можем использовать отрицательные индексы в срезах. Например, мы можем нарезать последние два элемента в списке, начав срез с -2 (второй последний элемент) и не указав индекс «до»; это берет ломтик до конца измерения.
Выполнение примера возвращает подмассив только с двумя последними элементами.
Двумерная нарезка
Давайте рассмотрим два примера двумерного среза, которые вы, скорее всего, будете использовать в машинном обучении.
Разделение функций ввода и вывода
Распространено загруженные данные на входные переменные (X) и выходную переменную (y).
Мы можем сделать это, разрезая все строки и все столбцы до, но перед последним столбцом, затем отдельно индексируя последний столбец.
Для входных объектов мы можем выбрать все строки и все столбцы, кроме последнего, указав ‘:’ в индексе строк и: -1 в индексе столбцов.
Для выходного столбца мы можем снова выбрать все строки, используя ‘:’, и индексировать только последний столбец, указав индекс -1.
Собрав все это вместе, мы можем разделить 3-колоночный 2D-набор данных на входные и выходные данные следующим образом:
При выполнении примера печатаются разделенные элементы X и y
Обратите внимание, что X — это двумерный массив, а y — это одномерный массив
Сплит поезд и тестовые ряды
Обычно загруженный набор данных разбивают на отдельные наборы поездов и тестов.
Это разделение строк, где некоторая часть будет использоваться для обучения модели, а оставшаяся часть будет использоваться для оценки мастерства обученной модели.
Для этого потребуется разрезать все столбцы, указав «:» во втором индексе измерения. Набор обучающих данных будет содержать все строки от начала до точки разделения.
Тестовым набором данных будут все строки, начиная с точки разделения до конца измерения.
Собрав все это вместе, мы можем разделить набор данных в надуманной точке разделения 2.
При выполнении примера выбираются первые две строки для обучения и последняя строка для набора тестов.
Манипуляции с формой
Как уже говорилось, у массива есть форма (shape), определяемая числом элементов вдоль каждой оси:
>>> a
array(,
],
,
]])
>>> a.shape
(2, 2, 3)
Форма массива может быть изменена с помощью различных команд:
>>> a.ravel() # Делает массив плоским
array()
>>> a.shape = (6, 2) # Изменение формы
>>> a
array(,
,
,
,
,
])
>>> a.transpose() # Транспонирование
array(,
])
>>> a.reshape((3, 4)) # Изменение формы
array(,
,
])
Порядок элементов в массиве в результате функции ravel() соответствует обычному «C-стилю», то есть, чем правее индекс, тем он «быстрее изменяется»: за элементом a следует a. Если одна форма массива была изменена на другую, массив переформировывается также в «C-стиле». Функции ravel() и reshape() также могут работать (при использовании дополнительного аргумента) в FORTRAN-стиле, в котором быстрее изменяется более левый индекс.
>>> a
array(,
,
,
,
,
])
>>> a.reshape((3, 4), order='F')
array(,
,
])
Метод reshape() возвращает ее аргумент с измененной формой, в то время как метод resize() изменяет сам массив:
>>> a.resize((2, 6))
>>> a
array(,
])
Если при операции такой перестройки один из аргументов задается как -1, то он автоматически рассчитывается в соответствии с остальными заданными:
Примеры работы с NumPy
Подытожим все вышесказанное. Вот несколько примеров полезных инструментов NumPy, которые могут значительно облегчить процесс написания кода.
Математические формулы NumPy
Необходимость внедрения математических формул, которые будут работать с матрицами и векторами, является главной причиной использования NumPy. Именно поэтому NumPy пользуется большой популярностью среди представителей науки. В качестве примера рассмотрим формулу , которая является центральной для контролируемых моделей машинного обучения, что решают проблемы регрессии:
Реализовать данную формулу в NumPy довольно легко:
Главное достоинство NumPy в том, что его не заботит, если и содержат одно или тысячи значение (до тех пор, пока они оба одного размера). Рассмотрим пример, последовательно изучив четыре операции в следующей строке кода:
У обоих векторов и по три значения. Это значит, что в данном случае равно трем. После выполнения указанного выше вычитания мы получим значения, которые будут выглядеть следующим образом:
Затем мы можем возвести значения вектора в квадрат:
Теперь мы вычисляем эти значения:
Таким образом мы получаем значение ошибки некого прогноза и за качество модели.
Представление данных NumPy
Задумайтесь о всех тех типах данных, которыми вам понадобится оперировать, создавая различные модели работы (электронные таблицы, изображения, аудио и так далее). Очень многие типы могут быть представлены как n-мерные массивы:
Создание массивов
В NumPy существует много способов создать массив. Один из наиболее простых — создать массив из обычных списков или кортежей Python, используя функцию numpy.array() (запомните: array — функция, создающая объект типа ndarray):
>>> import numpy as np >>> a = np.array() >>> a array() >>> type(a) <class 'numpy.ndarray'>
Функция array() трансформирует вложенные последовательности в многомерные массивы. Тип элементов массива зависит от типа элементов исходной последовательности (но можно и переопределить его в момент создания).
>>> b = np.array(, 4, 5, 6]])
>>> b
array(,
])
Можно также переопределить тип в момент создания:
>>> b = np.array(, 4, 5, 6]], dtype=np.complex)
>>> b
array(,
])
Функция array() не единственная функция для создания массивов. Обычно элементы массива вначале неизвестны, а массив, в котором они будут храниться, уже нужен. Поэтому имеется несколько функций для того, чтобы создавать массивы с каким-то исходным содержимым (по умолчанию тип создаваемого массива — float64).
Функция zeros() создает массив из нулей, а функция ones() — массив из единиц. Обе функции принимают кортеж с размерами, и аргумент dtype:
>>> np.zeros((3, 5))
array(,
,
])
>>> np.ones((2, 2, 2))
array(,
],
,
]])
Функция eye() создаёт единичную матрицу (двумерный массив)
>>> np.eye(5)
array(,
,
,
,
])
Функция empty() создает массив без его заполнения. Исходное содержимое случайно и зависит от состояния памяти на момент создания массива (то есть от того мусора, что в ней хранится):
>>> np.empty((3, 3))
array(,
,
])
>>> np.empty((3, 3))
array(,
,
])
Для создания последовательностей чисел, в NumPy имеется функция arange(), аналогичная встроенной в Python range(), только вместо списков она возвращает массивы, и принимает не только целые значения:
>>> np.arange(10, 30, 5) array() >>> np.arange(, 1, 0.1) array()
Вообще, при использовании arange() с аргументами типа float, сложно быть уверенным в том, сколько элементов будет получено (из-за ограничения точности чисел с плавающей запятой). Поэтому, в таких случаях обычно лучше использовать функцию linspace(), которая вместо шага в качестве одного из аргументов принимает число, равное количеству нужных элементов:
>>> np.linspace(, 2, 9) # 9 чисел от 0 до 2 включительно array()
fromfunction(): применяет функцию ко всем комбинациям индексов
Многомерный массив
Как и в случае с двумерным массивом, представленным в виде сложного списка, многомерный массив реализуется по принципу «списков внутри списка». Следующий пример наглядно демонстрирует создание трехмерного списка, который заполняется нулевыми элементами при помощи трех циклов for. Таким образом, программа создает матрицу с размерностью 5×5×5.
d1 = []
for k in range(5):
d2 = []
for j in range(5):
d3 = []
for i in range(5):
d3.append(0)
d2.append(d3)
d1.append(d3)
Аналогично двумерному массиву, обратиться к ячейке построенного выше объекта можно с помощью индексов в квадратных скобках, например, d1.
Двумерные массивы
Выше везде элементами массива были числа. Но на самом деле элементами массива может быть что угодно, в том числе другие массивы. Пример:
a = b = c = z =
Что здесь происходит? Создаются три обычных массива , и , а потом создается массив , элементами которого являются как раз массивы , и .
Что теперь получается? Например, — это элемент №1 массива , т.е. . Но — это тоже массив, поэтому я могу написать — это то же самое, что , т.е. (не забывайте, что нумерация элементов массива идет с нуля). Аналогично, и т.д.
То же самое можно было записать проще:
z = , , ]
Получилось то, что называется двумерным массивом. Его можно себе еще представить в виде любой из этих двух табличек:
Первую табличку надо читать так: если у вас написано , то надо взять строку № и столбец №. Например, — это элемент на 1 строке и 2 столбце, т.е. -3. Вторую табличку надо читать так: если у вас написано , то надо взять столбец № и строку №. Например, — это элемент на 2 столбце и 1 строке, т.е. -3. Т.е. в первой табличке строка — это первый индекс массива, а столбец — второй индекс, а во второй табличке наоборот. (Обычно принято как раз обозначать первый индекс и — второй.)
Когда вы думаете про таблички, важно то, что питон на самом деле не знает ничего про строки и столбцы. Для питона есть только первый индекс и второй индекс, а уж строка это или столбец — вы решаете сами, питону все равно
Т.е. и — это разные вещи, и питон их понимает по-разному, а будет 1 номером строки или столбца — это ваше дело, питон ничего не знает про строки и столбцы. Вы можете как хотите это решить, т.е. можете пользоваться первой картинкой, а можете и второй — но главное не запутайтесь и в каждой конкретной программе делайте всегда всё согласованно. А можете и вообще не думать про строки и столбцы, а просто думайте про первый и второй индекс.
Обратите, кстати, внимание на то, что в нашем примере (массив, являющийся вторым элементом массива ) короче остальных массивов (и поэтому на картинках отсутствует элемент в правом нижнем углу). Это общее правило питона: питон не требует, чтобы внутренние массивы были одинаковой длины
Вы вполне можете внутренние массивы делать разной длины, например:
x = , , , [], ]
здесь нулевой массив имеет длину 4, первый длину 2, второй длину 3, третий длину 0 (т.е. не содержит ни одного элемента), а четвертый длину 1. Такое бывает надо, но не так часто, в простых задачах у вас будут все подмассивы одной длины.
(На самом деле даже элементы одного массива не обязаны быть одного типа. Можно даже делать так: , здесь нулевой элемент массива — сам является массивом, а еще два элемента — просто числа. Но это совсем редко бывает надо.)
Начинаем работу
Основным объектом NumPy является однородный многомерный массив (в numpy называется numpy.ndarray). Это многомерный массив элементов (обычно чисел), одного типа.
Наиболее важные атрибуты объектов ndarray:
ndarray.ndim — число измерений (чаще их называют «оси») массива.
ndarray.shape — размеры массива, его форма. Это кортеж натуральных чисел, показывающий длину массива по каждой оси. Для матрицы из n строк и m столбов, shape будет (n,m). Число элементов кортежа shape равно ndim.
ndarray.size — количество элементов массива. Очевидно, равно произведению всех элементов атрибута shape.
ndarray.dtype — объект, описывающий тип элементов массива. Можно определить dtype, используя стандартные типы данных Python. NumPy здесь предоставляет целый букет возможностей, как встроенных, например: bool_, character, int8, int16, int32, int64, float8, float16, float32, float64, complex64, object_, так и возможность определить собственные типы данных, в том числе и составные.
ndarray.itemsize — размер каждого элемента массива в байтах.
Как создаются матрицы в Python?
Добавление и модификация массивов или матриц (matrix) в Python осуществляется с помощью библиотеки NumPy. Вы можете создать таким образом и одномерный, и двумерный, и многомерный массив. Библиотека обладает широким набором пакетов, которые необходимы, чтобы успешно решать различные математические задачи. Она не только поддерживает создание двумерных и многомерных массивов, но обеспечивает работу однородных многомерных матриц.
Чтобы получить доступ и начать использовать функции данного пакета, его импортируют:
import numpy as np
Функция array() — один из самых простых способов, позволяющих динамически задать одно- и двумерный массив в Python. Она создаёт объект типа ndarray:
array = np.array(/* множество элементов */)
Для проверки используется функция array.type() — принимает в качестве аргумента имя массива, который был создан.
Если хотите сделать переопределение типа массива, используйте на стадии создания dtype=np.complex:
array2 = np.array([ /*элементы*/, dtype=np.complex)
Когда стоит задача задать одномерный или двумерный массив определённой длины в Python, и его значения на данном этапе неизвестны, происходит его заполнение нулями функцией zeros(). Кроме того, можно получить матрицу из единиц через функцию ones(). При этом в качестве аргументов принимают число элементов и число вложенных массивов внутри:
np.zeros(2, 2, 2)
К примеру, так в Python происходит задание двух массивов внутри, которые по длине имеют два элемента:
array(] ]] )
Если хотите вывести одно- либо двумерный массив на экран, вам поможет функция print(). Учтите, что если матрица слишком велика для печати, NumPy скроет центральную часть и выведет лишь крайние значения. Дабы увидеть массив полностью, используется функция set_printoptions(). При этом по умолчанию выводятся не все элементы, а происходит вывод только первой тысячи. И это значение массива указывается в качестве аргумента с ключевым словом threshold.
Глубокое и поверхностное копирование объектов с помощью copy
Как мы уже хорошо уяснили, операция присваивания не приводит к копированию объекта, а лишь создаёт ссылку на этот объект. Но если мы работаем с изменяемыми коллекциями или коллекциями, которые содержат изменяемые элементы, нам может понадобиться такая копия, которую мы сможем изменить, не меняя оригинал. Здесь нам тоже поможет copy, выполняющий как поверхностное, так и глубокое копирование:
• copy.copy(a) — возвращает поверхностную копию a;
• copy.deepcopy(a) — возвращает полную копию a.
Если же объект скопировать невозможно, возникает исключение copy.error.
В принципе, разница между глубоким и поверхностным копированием существенна лишь для составных объектов, которые содержат изменяемые объекты (допустим, список списков). При этом:
1) поверхностная копия позволяет создать новый составной объект, а потом (если это возможно) вставляет в него ссылки на объекты, которые находятся в оригинале;
2) глубокая копия позволяет создать новый составной объект, а потом рекурсивно вставляет в него копии объектов, которые находятся в оригинале.
>>> import copy >>> test_1 = 1, 2, 3, 1, 2, 3]] >>> test_copy = copy.copy(test_1) >>> print(test_1, test_copy) 1, 2, 3, 1, 2, 3]] 1, 2, 3, 1, 2, 3]] >>> test_copy3.append(4) >>> print(test_1, test_copy) 1, 2, 3, 1, 2, 3, 4]] 1, 2, 3, 1, 2, 3, 4]] >>> test_1 = 1, 2, 3, 1, 2, 3]] >>> test_deepcopy = copy.deepcopy(test_1) >>> test_deepcopy3.append(4) >>> print(test_1, test_deepcopy) 1, 2, 3, 1, 2, 3]] 1, 2, 3, 1, 2, 3, 4]]
При выполнении глубокого копирования возможны проблемы (их нет у поверхностного копирования):
— рекурсивные объекты могут привести к рекурсивному циклу;
— т. к. глубокая копия копирует всё, она способна скопировать слишком много, к примеру, административные структуры данных.
Однако в случае возникновения проблем нам поможет функция deepcopy, которая устраняет эти сложности:
— посредством хранения «memo» словаря объектов;
— позволяя классам, которые определяет пользователь, переопределять операцию копирования либо набор копируемых компонентов.
>>> r = 1, 2, 3 >>> r.append(r) >>> print(r) 1, 2, 3, ...]] >>> p = copy.deepcopy(r) >>> print(p) 1, 2, 3, ...]]
В результате, не копируются типы вроде классов, функций, модулей, методов, стековых кадров, окон, сокетов и т. п.
Что же, теперь, надеемся, вы получили представление о копировании массивов и объектов в Python. Если хотите знать больше, к вашим услугам специализированный курс для продвинутых разработчиков:
При написании материала использовались статьи:
— «Модуль copy — поверхностное и глубокое копирование объектов»;
— «Копии и представления массивов».
Использование sorted() для итерируемых объектов Python
Python использует несколько чрезвычайно эффективных алгоритмов сортировки. Например, метод использует алгоритм под названием Timsort (который представляет собой комбинацию сортировки вставкой и сортировки слиянием) для выполнения высокооптимизированной сортировки.
С помощью этого метода можно отсортировать любой итерируемый объект Python, например список или массив.
import array
# Declare a list type object
list_object =
# Declare an integer array object
array_object = array.array('i', )
print('Sorted list ->', sorted(list_object))
print('Sorted array ->', sorted(array_object))
Вывод:
Sorted list -> Sorted array ->
Ways to Print an Array in Python
Now, let us look at some of the ways to print both 1D as well as 2D arrays in Python. Note: these arrays are going to be implemented using lists.
Directly printing using the print() method
We can directly pass the name of the array(list) containing the values to be printed to the method in Python to print the same.
But in this case, the array is printed in the form of a list i.e. with brackets and values separated by commas.
arr =
arr_2d = ,]
print("The Array is: ", arr) #printing the array
print("The 2D-Array is: ", arr_2d) #printing the 2D-Array
Output:
The Array is: The 2D-Array is: , ]
Here, is a one-dimensional array. Whereas, is a two-dimensional one. We directly pass their respective names to the method to print them in the form of a list and list of lists respectively.
Using for loops in Python
We can also print an array in Python by traversing through all the respective elements using loops.
Let us see how.
arr =
arr_2d = ,]
#printing the array
print("The Array is : ")
for i in arr:
print(i, end = ' ')
#printing the 2D-Array
print("\nThe 2D-Array is:")
for i in arr_2d:
for j in i:
print(j, end=" ")
print()
Output:
The Array is : 2 4 5 7 9 The 2D-Array is: 1 2 3 4
In the code above we traverse through the elements of a 1D as well as a 2D Array using for loops and print the corresponding elements in our desired form.
Добавление нового массива
Перед процессом создание нового массива, необходимо выполнить некоторые действия. Для начала, стоит произвести импорт библиотеки, которая отвечает за работу с подобными объектами. Чтобы выполнить это действие, нужно добавить в файл программы следующую строку: from array import *.
Исходя из того, что массивы предназначены для работы с одним типом данных, то и, соответственно, размер ячеек этих данных также будет одинаков.
Для создания нового массива данных используется такая функция, как «array». Ниже представлен пример того, как заполняется массив с помощью перечисленных действий:
from array import *data = array(‘i’, )
Функция «array» способна принимать два аргумента, одним из них является вид массива, который создается, другим – исходный перечень значений массива. В этом примере i является числом, размер которого составляет 2 б. Стоит отметить, что можно использовать не только этот примитив, но и другие – c, f и т. д.
Действия для добавления нового элемента
Для того, чтобы в массиве появился новый элемент, необходимо воспользоваться таким методом, как «insert». Это делается с помощью ввода в созданный ранее объект двух значений, являющихся аргументами. Цифра 3 представляет собой не что иное, как само значение, а 4 указывает на место в массиве, где будет располагаться элемент, т. е. его индекс.
Действия для удаления нового элемента
В рассматриваемом языке программирования избавиться от лишних элементов можно посредством такого метода, как «pop». Данный метод имеет аргумент (3) и может быть вызван через объект, который создавался ранее, т. е. способом, аналогичным добавлению нового элемента.
data.pop(3)
После того, как произошло удаление лишнего, в массиве происходит сдвиг его содержимого таким образом, чтобы число свободных ячеек памяти совпало с текущим количеством элементов.
Проверка
Зачастую возникает необходимость проверки данных при работе с любой программой, которая проводится путем вывода на экран. Эта операция может быть совершена с помощью такой команды, как «print». Аргументом для этой функции является элемент массива, созданного ранее.
В нижеприведенном примере видно, что обработка массива происходит с помощью цикла «for», в котором любой элемент массива идентификатором i для передачи в «print».