Поисковые подсказки яндекс и google: сбор, анализ и продвижение
Содержание:
- Как получить список поисковых подсказок
- Советы и рекомендации по использованию программ для парсинга
- Определение «скрытых» данных на уровне ключевых слов
- Сбор поисковых подсказок Яндекса и Гугла
- Каталог спортивных товаров Триал Спорт Тольятти
- Сбор частотностей из Вордстата
- Оффлайн парсеры
- 8 лайфхаков для ресторанного SMM
- Сбор поисковых подсказок
- Что это
- Что такое семантическое ядро сайта
- СловоЁБ — эффективный анализ ключевых слов
- Группировка запросов
- Режимы сбора подсказок
- Сбор маркерных запросов
- Что делаем с подсказками дальше
- Что такое Яндекс Wordstat
- Что можно делать с помощью SQL запросов
- Зачем использовать программу Key Collector
- Парсеры сайтов в зависимости от используемой технологии
- Как попасть в ТОП подсказок
Как получить список поисковых подсказок
Можно получить несколькими способами:
- Используя блок дополнительного поиска в системе Google «Вместе с … часто ищут». Для этого вводится запрос, и можно посмотреть, что ищут вместе с ним.
Такой вид не совсем удобен, поскольку, во-первых, показывает всего около десятка подсказок, что очень мало для создания семантического ядра сайта. Во-вторых, каждую фразу приходится набивать отдельно, что занимает много времени. Выгрузить результаты по нескольким запросам сразу нельзя.
2. Посредством инструментов для парсера подсказок поисковых систем:
Ubersuggest — позволяет увидеть информацию из поиска по новостям, изображениям и видео поисковой системы. Нужно ввести ключевое слово в строку поиска и задать язык.
Этот сервис подскажет, какие слова пользователи ищут вместе с заданными «ключевиками». Дополнительные слова при этом разделяются от заданного основного знаком «+». Сортировка по алфавиту делает работу с данными удобной для SEO-оптимизатора.
- Keyword Tool является бесплатным сервисом. Он основан на подсказках Google для разных регионов и языков данной поисковой системы. Также сервис позволяет увидеть семантику из Bing, AppStore и YouTube. Стандартно вводится слово в строку поиска, производится отбор по базе данных и языку.
- Словодер — программа, позволяющая работать сразу с несколькими поисковыми системами, поскольку работает через прокси-сервер. Для начала работы необходимо скачать программу, после ее запуска ввести слово для поиска и выбрать нужный поисковик — поисковые подсказки Яндекс , Google, Mail, Rambler, Yahoo, Nigma. Затем нужно нажать на кнопку «Парсить» и подождать вывода результатов.
- avtodreem, чаще всего можно встретить в поисковой выдаче по запросу «как попасть в подсказки».
Советы и рекомендации по использованию программ для парсинга
Специалисты советуют сочетать ручной и автоматический выбор запросов для составления семантического ядра, особенно для новичков. Пользуясь штатным инструментом Яндекс Вордстат Ассистент, вы нарабатываете навыки интуитивного подбора поисковых фраз, которые приводят на сайт целевых клиентов с помощью средне- и низкочастотных ключей. Высокочастотные фразы не всегда работают, особенно в конкурентной нише.
Если у вас нет времени на ручной парсинг в Яндекс Вордстат, используйте специальные инструменты. В интернете можно найти различное программное обеспечение, но большинство русскоязычных специалистов по SEO-оптимизации делают парсинг выдачи Яндекса с помощью Key Collector.
Это десктопный продукт, позволяющий создавать и хранить в локальной памяти компьютера проекты для каждого сайта, загружать и сохранять файлы и делать парсинг ключевых слов в соответствии с региональными настройками. Программа требует привязки к аккаунту. Для работы с ключевыми поисковыми запросами в Кей Коллекторе имеются пиктограммы основных поисковых систем в Рунете (в нашем случае это Yandex-парсер, хотя можно выбрать Google, Bing и другие).

Среди других полезных сервисов для SEO такие:
- Serpstat – многофункциональная платформа для профессионалов, имеющая триальную версию с ограниченным функционалом, а также платную подписку от 19 до 299$ в месяц;
- Ahrefs – веб-сервис с множеством полезных опций, включая мониторинг ниши, анализ конкурентов и улучшение индексации сайта. Для сбора семантического ядра предусмотрен инструмент Keywords Explorer. Протестировать его можно от 7$ в неделю;
- Semrush — аналог Ahrefs по части функционала, более дорогой по тарифам (от 99$ и выше).
Специалисты утверждают, что Кей Коллектор – это самая удобная и функциональная программа, позволяющая значительно облегчить жизнь оптимизатора. У нее есть множество полезных опций для точной настройки параметров парсера Yandex (например, глубины поиска, избирательного поиска запросов по базовой частотности и т.п.).
Но у программы есть нюанс – она платная. Стоимость лицензии составляет 1800-1900 рублей по электронному и безналичному расчету соответственно.
Совет! Если по какой-то причине вы не хотите пользоваться этим продуктом, можете попробовать его бесплатный аналог «Словоёб». Подойдет и более простой вариант — Букварикс – бесплатный сервис для сбора ключевых слов и формирования семантического ядра.
Парсинг Яндекс Вордстат можно делать самостоятельно и с помощью специальных программ. Ручной сбор посредством инструмента Wordstat Assistant оправдывает себя в том случае, если ваша ниша имеет узкую направленность и мало конкурентов, а перечень поисковых запросов относительно невелик. При больших объемах работ рекомендуется пользоваться специальными программами для парсинга и аналитики.
Определение «скрытых» данных на уровне ключевых слов
В Google Analytics есть возможность подгрузить данные из Search Console. Но вы не увидите ничего нового — все те же страницы, CTR, позиции и показы. А было бы интересно посмотреть, какой процент отказов при переходе по тем или иным ключевым словам и, что еще интересней, сколько достигнуто целей по ним.
Тут поможет шаблон от Sarah Lively, который описан в статье для MOZ.
Для начала работы установите дополнения для Google Sheets:
- Google Analytics Spreadsheet Add-on;
- Search Analytics for Sheets (если вы использовали первые два шаблона, то это дополнение у вас уже есть).
Шаг 1. Настраиваем выгрузку данных из Google Analytics
Создайте новую таблицу, откройте меню «Дополнения» / «Google Analytics» и выберите пункт «Create new report».
Заполняем параметры отчета:
- Name — «Organic Landing Pages Last Year»;
- Account — выбираем аккаунт;
- Property — выбираем ресурс;
- View — выбираем представление.
Нажимаем «Create report». Появляется лист «Report Configuration». Вначале он выглядит так:
Но нам нужно, чтобы он выглядел так (параметры выгрузки вводим вручную):
Просто скопируйте и вставьте параметры отчетов (и удалите в поле Limit значение 1000):
| Report Name | Organic Landing Pages Last Year | Organic Landing Pages This Year |
| View ID | //здесь будет ваш ID в GA!!! | //здесь будет ваш ID в GA!!! |
| Start Date | 395daysAgo | 30daysAgo |
| End Date | 365daysAgo | yesterday |
| Metrics | ga:sessions, ga:bounces, ga:goalCompletionsAll | ga:sessions, ga:bounces, ga:goalCompletionsAll |
| Dimensions | ga:landingPagePath | ga:landingPagePath |
| Order | -ga:sessions | -ga:sessions |
| Filters | ||
| Segments | sessions::condition::ga:medium==organic | sessions::condition::ga:medium==organic |
После этого в меню «Дополнения» / «Google Analytics» нажмите «Run reports». Если все хорошо, вы увидите такое сообщение:
Также появится два новых листа с названиями отчетов.
Шаг 2. Выгрузка данных из Search Console
Работаем в том же файле. Переходим на новый лист и запускаем дополнение Search Analytics for Sheets.
Параметры выгрузки:
- Verified Site — указываем сайт;
- Date Range — задаем тот же период, что и в отчете «Organic Landing Pages This Year» (в нашем случае — последний месяц);
- Group By — «Query», «Page»;
- Aggregation Type — «By Page»;
- Results Sheet — выбираем текущий «Лист 1».
Выгружаем данные и переименовываем «Лист 1» на «Search Console Data». Получаем такую таблицу:
Для приведения данных в сопоставимый с Google Analytics вид меняем URL на относительные — удаляем название домена (через функцию замены меняем домен на пустой символ).
После изменения URL должны иметь такой вид:
Шаг 3. Сводим данные из Google Analytics и Search Console
Копируем шаблон Keyword Level Data. Открываем его и копируем лист «Keyword Data» в наш рабочий файл. В столбцы «Page URL #1» и «Page URL #2» вставляем относительные URL страниц, по которым хотим сравнить статистику.
По каждой странице подтягивается статистика из Google Analytics, а также 6 самых популярных ключей, по которым были переходы. Конечно, это не детальная статистика по каждому ключу, но все же это лучше, чем ничего.
При необходимости вы можете доработать шаблон — изменить показатели, количество выгружаемых ключей и т. п. Как это сделать, детально описано в оригинальной статье.
Как видите, для работы с ключами не обязательно сразу доставать кошелек. Есть немало простых решений. Следите за нашими публикациями — мы еще не раз поделимся полезностями.
Сбор поисковых подсказок Яндекса и Гугла
Сейчас в Интернете есть сервисы и программы, которые осуществляют сбор поисковых подсказок Яндекса и Гугла. Далее, нами будут рассмотрены такие сервисы и программа:
- Пиксель Тулс;
- Раш Аналитикс;
- Программа Кей Коллектор.
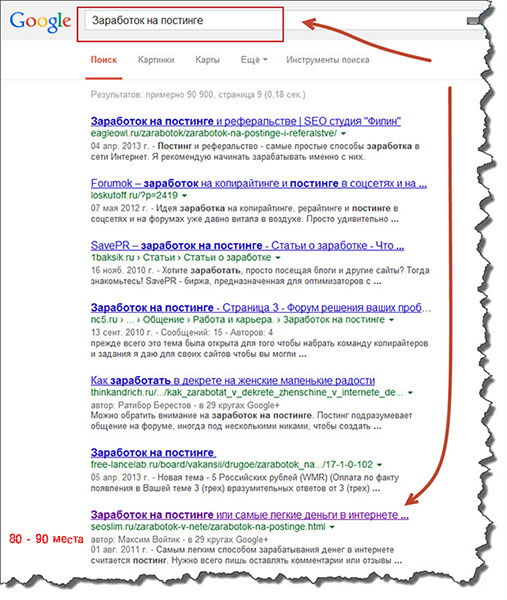
Парсер поисковых подсказок выглядит в Яндексе таким образом (Скрин 1).
Например, мы введём поисковый запрос – «заработок в Интернете». И если нажать на клавиатуре кнопку «Пробел» можно получить сразу ещё 9 таких аналогичных подсказок. Тоже самое дело обстоит и с Гуглом (Скрин 2).
Правда он больше подходит для продвижения иностранных ресурсов, чем сайтов, блогов русскоязычного Интернета. Веб-мастера в основном «упираются» на Яндекс, но о Гугле не забывают.
Каталог спортивных товаров Триал Спорт Тольятти
Сбор частотностей из Вордстата
Он нужен, чтобы узнать точное количество запросов по ключам.
Нажмите кнопку с таким значком:
Программа предлагает разные варианты – собрать:
- Все виды частотностей
- Базовые виды частотности
- Частотности фраз в кавычках (то есть в фразовом соответствии)
- Частотности фраз в точном соответствии (конкретно по данном словоформе).
Выберите последний вариант и дождитесь окончания сбора данных. Результат будет выглядеть примерно так (на том же примере с пиццей):
Далее вы можете сразу очистить результаты от явно нецелевых запросов прямо в программе Словоеб, или оставить это на потом – удалить мусорные фразы из экспортированного Excel-файла.
Итак, сбор семантики завершен. Результаты парсинга можно сохранить на свой компьютер для дальнейшего использования в рекламных кампаниях.
Кликните кнопку экспорта:
Допустим, вы в самом начале настройки выбрали для экспорта формат csv – на выходе получаете CSV-файл с семантикой.
Если вы распределяли ключи по группам, в этом файле каждый лист соответствует отдельной группе.
Вот и всё, что нужно знать про Словоеб и как с ним работать.
Оффлайн парсеры
Возможность парсинга Яндекс Вордстат без доступа к интернету или при его низкой скорости – одно из требований к современным инструментам СЕО анализа. Технически это реализовано просто – на компьютер или аналогичное устройство, скачивается базы Wordstat и затем с помощью программы происходит выборка ключевых слов.
Букварикс десктопная версия
Впервые полноценный десктопный вариант представили разработчики «Букварикс». Однако уже в октябре 2017 года этот проект был «заморожен», ПО и базы данных не обновляются. Компания предлагает все инструменты в онлайн-режиме. Скачать приложение можно на старой версии официального сайта, использование бесплатное.
Что нужно учитывать при использовании десктопной версии:
- скачиваемый объем – около 30 Гбайт;
- скачать можно только с Яндекс.Диска, состоит из 20 частей;
- последняя дата обновления БД – 1 октября 2017 г.
Информация в этой версии устарела, возможно использование как вспомогательного инструмента.
8 лайфхаков для ресторанного SMM
Сбор поисковых подсказок
Сбор поисковых подсказок нужен для того, чтобы расширить список ключевых запросов, и является очень полезным инструментом, так как при парсинге Яндекс.Вордстат пропускаются фразы содержащие количество слов больше 7. Часто такие фразы представляют собой популярные информационные запросы, которые могут служить дополнительным источником трафика.
В начале работы в настройках нужно установить время ожидания между запросами, которые отправляет программа к поисковым системам при получении поисковых подсказок. Существует опасность блокирования IP-адреса из-за слишком большого количества обращений при парсинге подсказок, поэтому лучше в настройках установить длительный разрыв между запросами от … до … мс.
Для того, чтобы собрать подсказки, нужно нажать на кнопку с иконкой трех разноцветных сот в группе кнопок «Сбор ключевых слов и статистики».
Затем поставить галочку напротив ПС. И запустить процесс сбора подсказок. После окончания процесса провести фильтрацию списка ключевых запросов, описанными способами выше и экспортировать оставшиеся ключевые фразы в файл для работы с Excel.
Что это
Являются удобным инструментом систем Яндекс и Гугл, позволяющим упростить и ускорить работу пользователей по поиску нужной информации среди множества запросов. При введении своего слова в строку поиска юзер видит все возможные варианты предложений по данной теме. При этом возможные варианты сменяются в зависимости от следующего введенного в поисковую строку браузера слова.
Первой их ввел Google. Произошло это в 2004 году. Еще через 4 года эти возможности системы были усовершенствованы. В 2010 году функционал стал еще лучше — теперь можно видеть загрузку результатов по мере того, как вводят каждое слово.
Механизм представляет только актуальные, то есть начальные, введенные фразы, навел SEO-оптимизаторов на мысль, что это можно использовать для создания семантического ядра сайта. При таком подходе контент сайта будет максимально релевантен запросу пользователей.
Что такое семантическое ядро сайта
Семантическое ядро – совокупность отдельных слов или словосочетаний, характеризующих тематику и структуру вашего сайта. Семантика – первоначально – область филологии, имеющая дело со смыслом слов. В настоящее время чаще понимается как изучение смысла вообще.
На основании этого можно сделать вывод, что понятия «семантическое ядро» и «смысловое ядро» – синонимы.
Цель создания семантического ядра сайта – наполнение его контентом, привлекательным для пользователей. Для этого необходимо узнать, по каким ключевым словам они будут искать информацию, размещенную на вашем сайте.
Оставить заявку
Подбор семантического ядра сайта предполагает распределение поисковых запросов или групп запросов по страницам таким образом, чтобы они максимально удовлетворяли целевую аудиторию.
Этого можно добиться двумя способами. Первый – проанализировать поисковые фразы пользователей и на их основе создать структуру сайта. Второй способ – сначала придумать каркас будущего сайта, а потом, после анализа, распределить по нему ключевые слова.
Каждый способ имеет право на существование, но второй более логичен: сначала вы создаете структуру сайта, а затем наполняете его поисковыми запросами, по которым потенциальные клиенты смогут найти нужный им контент через поисковые системы.
Так вы проявляете качество проактивности – самостоятельно определяете, какую информацию донести до посетителей сайта. В противном случае, создавая структуру сайта на основе ключевых слов, вы лишь подстраиваетесь под окружающую действительность.
Рекомендуемые статьи по данной теме:
- Практические советы по раскрутке сайта
- Анализ контента сайта: 9 этапов + сервисы помощники
- Все, что вы хотели знать про услуги продвижения сайта
Есть кардинальное отличие между подходом к созданию семантического ядра сайта специалиста по SEO и маркетолога.
Классический оптимизатор скажет вам: чтобы создать сайт, нужно отобрать фразы и слова из поисковых запросов, по которым можно попасть в ТОП поисковой выдачи. Затем на их основе сформировать структуру будущего сайта и распределить ключевые слова по страницам. Контент страниц создается под выбранные ключевики.
Маркетолог или предприниматель подойдет к вопросу создания сайта иначе. Сначала он задумается над тем, для чего нужен сайт, какую информацию он будет нести пользователям. Потом придумает ориентировочную структуру сайта и перечень страниц. На следующем этапе он займется созданием семантического ядра сайта, чтобы понять, по каким поисковым запросам потенциальные клиенты ищут информацию.
Каковы недостатки работы с семантическим ядром с позиции специалиста по SEO? В первую очередь, при таком подходе качество информации на сайте значительно ухудшается.
Компания должна сама решать, что говорить клиентам, а не выдавать контент в качестве реакции на наиболее популярные поисковые запросы. Подобная слепая оптимизация может привести к тому, что отсеется часть перспективных запросов с низкими показателями частотности.
Результатом создания семантического ядра является перечень ключевых слов, которые распределены по страницам сайта. В этом списке указывается URL страниц, ключевые слова и уровень частотности их запросов.
СловоЁБ — эффективный анализ ключевых слов
СловоЁБ — это новый программный продукт, позволяющий эффективно парсить и обрабатывать слова. Среди основных инструментов СловоЁБа числятся:
1) парсинг сервиса Yandex.Wordstat: «плоский» и «объемным» поиск;
2) статистика LiveInternet: раскладка по популярности запросов в поисковых системах;
3) позволяет определять целевую страницу под запрос в Яндекс и Гугл.
4) позволяет парсить поисковые подсказки.
5) позволяет парсить конкуренцию.
Программа поддерживает ручную обработку капчи Яндекса, а также работу через прокси-серверы. В качестве альтернативы многопоточности выступает опция «Множитель скорости». Программа автоматически уменьшает время таймаута на количество добавленных прокси-серверов, в результате чего достигается не худшее увеличение скорости обработки данных.
Группировка запросов
После фильтрации запросов нужно посчитать для них отношение БЧ к ТЧ и распределить по смысловым группам.
Отношение базовой частотности к точной показывает насколько эффективным является поисковый запрос. Если значение отношения БЧ к ТЧ большое, скорее всего запрос «пустой» и не стоит его использовать при продвижении страницы сайта.
Процесс группировки запросов занимает большое количество времени, чтобы сократить его, используется приложение «Подбор и кластеризация запросов» от Megaindex. Все что нужно сделать, это ввести доменное имя целевого сайта, добавить свой список запросов и запустить процесс кластеризации. Через некоторое время получается файл с разгруппированными запросами, которые нужно сопоставить с исходным файлом запросов, в котором есть значения частотностей и отношение БЧ к ТЧ. В данном случае пригодится функция ВПР для Excel. Функция позволит найти и перенести искомые значения частотностей из столбцов общего списка запросов в столбцы списка разгруппированных запросов.
Вводим формулу в первую ячейку столбца базовых частотностей:
- искомое значение – нужно выделить первую фразу в столбце кластеризованных запросов;
- таблица – выделить таблицу общего списка запросов;
- номер столбца – ввести номер столбца (например, столбец с базовой частотностью второй);
- интервальный просмотр – поставить 0.
Затем нужно протянуть значения вниз, предварительно поставив знаки доллара у выделенного интервала таблицы.
После того, как все столбцы со значениями будут перенесены, их нужно выделить и нажать копировать. Затем, нажав правую кнопку мышки, выбрать пункт «Специальная вставка» и там выбрать вариант для вставки «значения».
Таким образом перенесенные значения больше не будут ссылаться на искомые и их можно будет удалить.
Когда запросы разбиты на группы, нужно отнести наиболее запрашиваемые в группу «А», а все остальные в группу «Б». Данные запросы будут продвигаться в первую очередь.
Теперь запросам группы «А» назначаются посадочные страницы.
Есть правило — один КС должен соответствовать одной посадочной странице. В одной группе может быть несколько запросов, которые содержат дополнительные слова или похожи между собой и отображают какую-то одну суть.
Например: «циклевка паркета в спб», «циклевка паркета в спб недорого цены», «циклевка пола», «циклевка пола цены спб».
Эти запросы относятся к одной посадочной странице, которая должна быть оптимизирована именно под них и должна быть релевантной, т.е. в полной мере давать ответ на запрос пользователя. Если пользователь не найдет для себя нужной информации и сразу покинет страницу, это будет плохим сигналом для ПС и может плохо повлиять на дальнейшее продвижение сайта.
Режимы сбора подсказок
С помощью !SEMTools для Excel можно собирать поисковые подсказки прямо на лист
Есть три режима парсинга на выбор:
- топ 10 по уже имеющемуся списку фраз
- сбор одного большого списка для одной фразы в двух режимах
- простом (1 символ)
- расширенном (2 символа)
В каждом режиме есть возможность выбрать регион из списка или задать код региона вручную.
Яндекс — топ 10 подсказок по имеющемуся списку
Выделяем список фраз для обработки, и процедура подбирает к каждой из них все подсказки Яндекса в заданном регионе без добавления каких-либо символов.
Собираем по 10 подсказок для каждой фразы, выбирая Волгоград в списке и задавая код Минска (157) вручную
Яндекс — сбор всех поисковых подсказок по одной фразе
Процедура сама переберет все символы кириллицы, латиницы и цифры после фразы и извлечет топ, отдаваемый движком поисковой системы, на лист. Нужно только ввести фразу и геокод локации, для которой будут собираться подсказки.
Парсер геозависимых подсказок Яндекса в Excel
Сбор маркерных запросов
Маркерные запросы – это запросы, которые четко отвечают продвигаемой странице. В большинстве случаев маркерным запросам соответствуют названия разделов, категорий, рубрик на сайте. Маркерные запросы нужны для того, чтобы в дальнейшем на их основе найти ключевые слова.
Например, на сайте имеется раздел «Циклевка паркета» — это наш маркер, с помощью которого формируются ключевые запросы, а именно: «циклевка паркета спб», «циклевка паркета спб недорого», «циклевка паркета цена» и т.д.
Маркерные запросы являются базовыми запросами по которым в дальнейшем будут собраны остальные ключевые запросы в автоматическом режиме. Поэтому, если упустить какой-то маркерный запрос, есть риск потерять значительный пласт ключевых запросов.
Одним из методов подбора маркерных запросов являются поисковые подсказки Яндекс. С их помощью можно найти другие часто задаваемые поисковые запросы. Как видно из рисунка ниже, при введении в поиск Яндекса ключевого запроса «ремонт паркета», получаем подсказки: «циклевка паркета», «шлифовка паркета», «укладка паркета» и др.
Вторым методом подбора маркерных запросов, является сервис wordstat.yandex.ru. При подборе запросов данным методом, удобно использовать Yandex Wordstat Assistant – это расширение для браузеров Google Chrome, Яндекс.Браузер и Opera. Перед началом поиска запросов нужно уточнить регион сбора данных. Далее, в строку поиска вводим маркерный запрос. В случае если какой-либо подобранный запрос из правой или левой колонки результатов подходит, нажимаем на иконку «+» напротив запроса, таким образом формируя полный список маркерных запросов.
Что делаем с подсказками дальше
Что делать с поисковыми подсказками, которые были Вами собраны? Специалисты рекомендуют собрать из них базовую статистику ключевых слов. Например, Вы получили только что данные ключевых слов по тем или иным подсказкам. Затем, нужно отобрать из ключей те запросы для статей, по которым они точно будут найдены в Сети. Для этого нужно рассматривать такие значения:
- частотность поисковых запросов;
- и количество просмотров за месяц.
Берём только те запросы, которые действительно используют люди для поиска в Интернете. Их частотность должны быть минимум 500 или 1000. Это значит, что Вашу статью по этому запросу точно станут искать и читать. Если частотность запроса будет ноль или меньше 100 трафика с неё не будет.
После сбора поисковых подсказок, можно составлять проекты (структуры) для статей и писать по ним статью. Эти подобранные ключи можно указывать в статьях и публиковать на блоге (сайте). Также Вы можете использовать мою книгу для написания правильной статьи – «Как написать и оптимизировать статью для блога».
Что такое Яндекс Wordstat
Яндекс Wordstat — бесплатный сервис, предназначенный для сбора статистики поисковых запросов в Яндексе. Он помогает рекламодателям и веб-мастерам понять популярность тех или иных ключей, выявить тренды, а также спрос на товары и услуги.
На деле Wordstat отображает прогнозное количество показов ключа в месяц на основе существующей статистики поиска, не включая РСЯ. В списках приводятся как различные вариации исследуемой фразы, так и те, которые наиболее часто ей сопутствуют. На этой основе можно делать выводы о смежных сферах интересов пользователей, которые затем использовать в кампании.
Благодаря сервису у специалиста появляется возможность:
- Собрать основу семантического ядра;
- Ранжировать популярность запросов по регионам;
- По устройствам;
- Выявить сезонность.
А с Calltouch можно анализировать результаты проделанной работы.
Сквозная аналитика
от 990 рублей в месяц
- Автоматически собирайте данные с рекламных площадок, сервисов и CRM в удобные отчеты
- Анализируйте воронку продаж от показов до ROI
- Настройте интеграции c CRM и другими сервисами: более 50 готовых решений
- Оптимизируйте свой маркетинг с помощью подробных отчетов: дашборды, графики, диаграммы
- Кастомизируйте таблицы, добавляйте свои метрики. Стройте отчеты моментально за любые периоды
Узнать подробнее
Между тем, существует ряд ограничений на работу с сервисом. Так, для качественного парсинга и анализа всех ключевых слов специалисту придётся использовать дополнительное программное обеспечение или плагины. Дело в том, что поиск по статистике Яндекса возможен только в ручном режиме. Процесс отсеивания и сбора ключевых фраз становится рутинным и трудоёмким в связи с невозможностью их загрузки на компьютер стандартными средствами сервиса. Из-за этого сбор семантического ядра через Wordstat не может быть произведён в полном объёме, если не прибегать к сторонним инструментам.
Вместе с этим, составление ядра затрудняется и ограничением по объёму выдачи. Если ваш запрос имеет много вариаций и весьма популярен в различных формах, вы вероятно не сможете проанализировать и использовать их все. Вордстат позволяет просмотреть лишь 2000 строк результата — 40 страниц по 50 фраз. Если за пределами остаются важные низкочастотные ключи, вы с трудом сможете их достать стандартными средствами.
Более того, для пользования Wordstat вы должны войти в Яндекс аккаунт. Уже в процессе работы с сервисом вы рискуете постоянно вводить капчу и даже быть забаненными в случае злоупотребления поиском однотипных запросов. Чтобы продолжать пользоваться сервисом в нормальном режиме, вы можете попробовать вводить слова в разных падежах. Например: вордстат Яндекс, вордстата Яндекса.

Что можно делать с помощью SQL запросов
Зачем использовать программу Key Collector
Если вы хотите написать одну статью, то подобрать для нее ключи можно с помощью описанных выше онлайн сервисов.
Но если вы наполняете содержимым целый сайт или хотите оказывать услуги по составлению семантического ядра, то без Key Collector вам не обойтись, так как этот софт может собирать статистику, рассчитывать конкуренцию, работать с поисковыми подсказками, другими сервисами и т.д.
Согласитесь, что намного проще открыть одну программу и работать только там, чем ходить по десяткам сайтов и где-то хранить полученные запросы.
А так я в Кей Коллекторе провожу парсинг и там же создаю группы, куда заношу полученные ключи для будущих статей.
Как найти ключи, определить частотность и уровень конкуренции
Работу в программе условно можно разделить на 2 способа:
- Парсинг ключей с помощью платных сервисов
- Парсинг ключей бесплатным Вордстатом
Первый способ. Так как программа универсальная, то в нее можно интегрировать такие сервисы для сбора ключей и статистики: SEMrush, SpyWords, Mutagen, Serpstat, MOAB.
Только предварительно не забудьте пройти регистрацию в том сервисе через который и будет происходить сбор данных. После чего в «Настройках» далее «Парсинг» далее «Платные API» указываем логи, пароль или токен.
После чего запускаем парсинг и указываем запрос, по которому надо собирать ядро.
В качестве примера был взят сервис Мутаген.
Как видим Мутаген все равно для парсинга будет использовать статистику от Яндекс Вордстат, поэтому не вижу смысла платить за это дополнительные деньги.
Ах да, так как сервисы платные, за каждую строчку будьте готовы потратить определенную сумму:
Цены на анализ запросов в Мутагене:
- Проверка конкуренции: 100 проверок — 30 руб.
- Парсер вордстат: 1 запрос — 0.02 руб.
Теперь представьте, если таких запросов будет 10 000, а если 100 000?
Второй способ.
Куда проще пользоваться бесплатным способом, это собирать ключевые слова и проверять конкуренцию через Yandex Wordstat.
Указали ключ и начинаем сбор. Все остальное сделает программа.
Единственное, что может принести неудобство, это когда при частом обращении к Яндексу, последний захочет убедиться, что вы не робот и покажет вам капчу.
Поэтому чтобы не отвлекаться на ее ввод, тем более если вы будите работаться с большим количеством слов, то лучше подключить к программе систему автоматического распознавания капчи.
Лично я для этого использую сервис ruCaptcha, где нам надо в настройках аккаунта получить API Key.
Кстати, если вы не хотите платить, то можете сначала заработать на разгадывании капчи. Лично я так и сделал, о чем рассказал в видео ниже.
Далее переходим в настройки Кей Коллектор и в меню «Антикапча» отмечаем пункт «Использовать ruCaptcha» и в поле настроек вводим полученный в личном кабинете API.
Теперь если в процессе парсинга будет встречаться капча, Key Collector не будет останавливаться, а сервис Рукапча все сделает за вас.
Как видно в ходе парсинга была разгадана 1 капча, а напротив отображается баланс, чтобы его было легче контролировать.
Если по ценам, то тут все очень даже лояльно:
Как видите, за очень малые деньги можно собирать СЯ с помощью стандартных функций программы, без подключения дорогих сервисов.
Парсеры сайтов в зависимости от используемой технологии
Парсеры на основе Python и PHP
Такие парсеры создают программисты. Без специальных знаний сделать парсер самостоятельно не получится. На сегодня самый популярный язык для создания таких программ Python. Разработчикам, которые им владеют, могут быть полезны:
- библиотека Beautiful Soup;
- фреймворки с открытым исходным кодом Scrapy, Grab и другие.
Заказывать разработку парсера с нуля стоит только для нестандартных задач. Для большинства целей можно подобрать готовые решения.
Парсеры-расширения для браузеров
Парсить данные с сайтов могут бесплатные расширения для браузеров. Они извлекают данные из html-кода страниц при помощи языка запросов Xpath и выгружают их в удобные для дальнейшей работы форматы — XLSX, CSV, XML, JSON, Google Таблицы и другие. Так можно собрать цены, описания товаров, новости, отзывы и другие типы данных.
Примеры расширений для Chrome: Parsers, Scraper, Data Scraper, kimono.
Парсеры сайтов на основе Excel
В таких программах парсинг с последующей выгрузкой данных в форматы XLS* и CSV реализован при помощи макросов — специальных команд для автоматизации действий в MS Excel. Пример такой программы — ParserOK. Бесплатная пробная версия ограничена периодом в 10 дней.
Парсинг при помощи Google Таблиц
В Google Таблицах парсить данные можно при помощи двух функций — importxml и importhtml.
Функция IMPORTXML импортирует данные из источников формата XML, HTML, CSV, TSV, RSS, ATOM XML в ячейки таблицы при помощи запросов Xpath. Синтаксис функции:
IMPORTXML("https://site.com/catalog"; "//a/@href")
IMPORTXML(A2; B2)
Расшифруем: в первой строке содержится заключенный в кавычки url (обязательно с указанием протокола) и запрос Xpath.
Знание языка запросов Xpath для использования функции не обязательно, можно воспользоваться опцией браузера «копировать Xpath»:
Вторая строка указывает ячейки, куда будут импортированы данные.
IMPORTXML можно использовать для сбора метатегов и заголовков, количества внешних ссылок со страницы, количества товаров на странице категории и других данных.
У IMPORTHTML более узкий функционал — она импортирует данные из таблиц и списков, размещенных на странице сайта. Синтаксис функции:
IMPORTHTML("https://https://site.com/catalog/sweets"; "table"; 4)
IMPORTHTML(A2; B2; C2)
Расшифруем: в первой строке, как и в предыдущем случае, содержится заключенный в кавычки URL (обязательно с указанием протокола), затем параметр «table», если хотите получить данные из таблицы, или «list», если из списка. Числовое значение (индекс) означает порядковый номер таблицы или списка в html-коде страницы.
Как попасть в ТОП подсказок
Поисковые системы противостоят тому, чтобы бренды находились в поисковых подсказках. Но в некоторых случаях их наличие вполне оправдано. Основные факторы, которые способствуют этому:
Активная внешняя реклама
Интернет-маркетологи формируют рекламное предложение так, чтобы пользователи были заинтересованы в поиске сайта. Такие запросы в поисковой строке улучшают позиции сайтов, так как выступают сигналом для поисковых систем о том, что пользователей интересует контент конкретного ресурса по тому или иному запросу.
Организация и проведения масштабных мероприятий
Старайтесь регулярно организовывать мероприятия для своей аудитории или выступать в качестве спонсора. Так, если ваш бренд будет на слуху, он заинтересует пользователей, которые захотят найти информацию о нем в поиске. Такие запросы способствуют популяризации и не исключено, что со временем ваш сайт будет демонстрироваться во многих поисковых подсказках.
Накрутка поисковых запросов с вашим брендом
Существует много сервисов, которые предлагают услуги по накрутке поисковых запросов. Все что требуется от вас — задать ключевые запросы и регион. Если с популярным запросом в подсказке появится ваш сайт, то на него увеличится количество переходов. Этот спрос может быть как временным, так и долгосрочным. При грамотной стратегии отмечается ощутимый прирост трафика по витальным запросам.
Витальные запросы — запросы поисковых систем, включающие только название компании или бренда без всяких дополнительных фраз.